1 Kafka概述
1.1 定义
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
1.2 消息队列
1.2.1 传统消息队列的应用场景
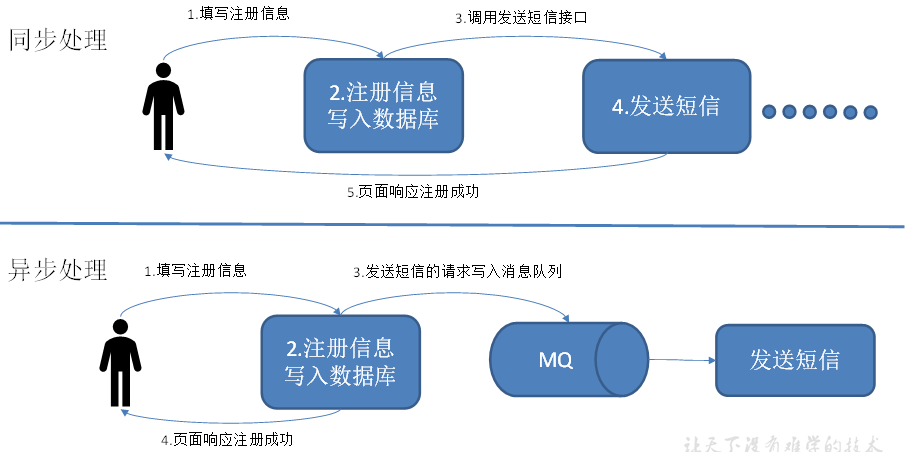
使用消息队列的好处
1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
1.2.2 消息队列的两种模式
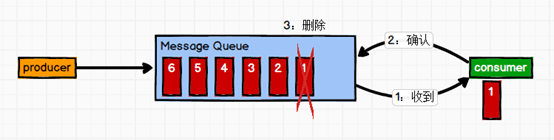
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。(这里注意是消费者主动拉取的)
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
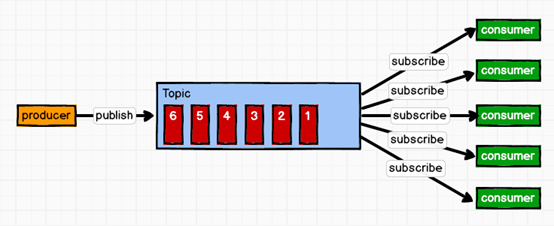
(2)发布/订阅模式(一对多,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。(这里注意数据也是消费者拉取的,因为消费者会一直轮询topic是否有消息)
1.3 Kafka基础架构
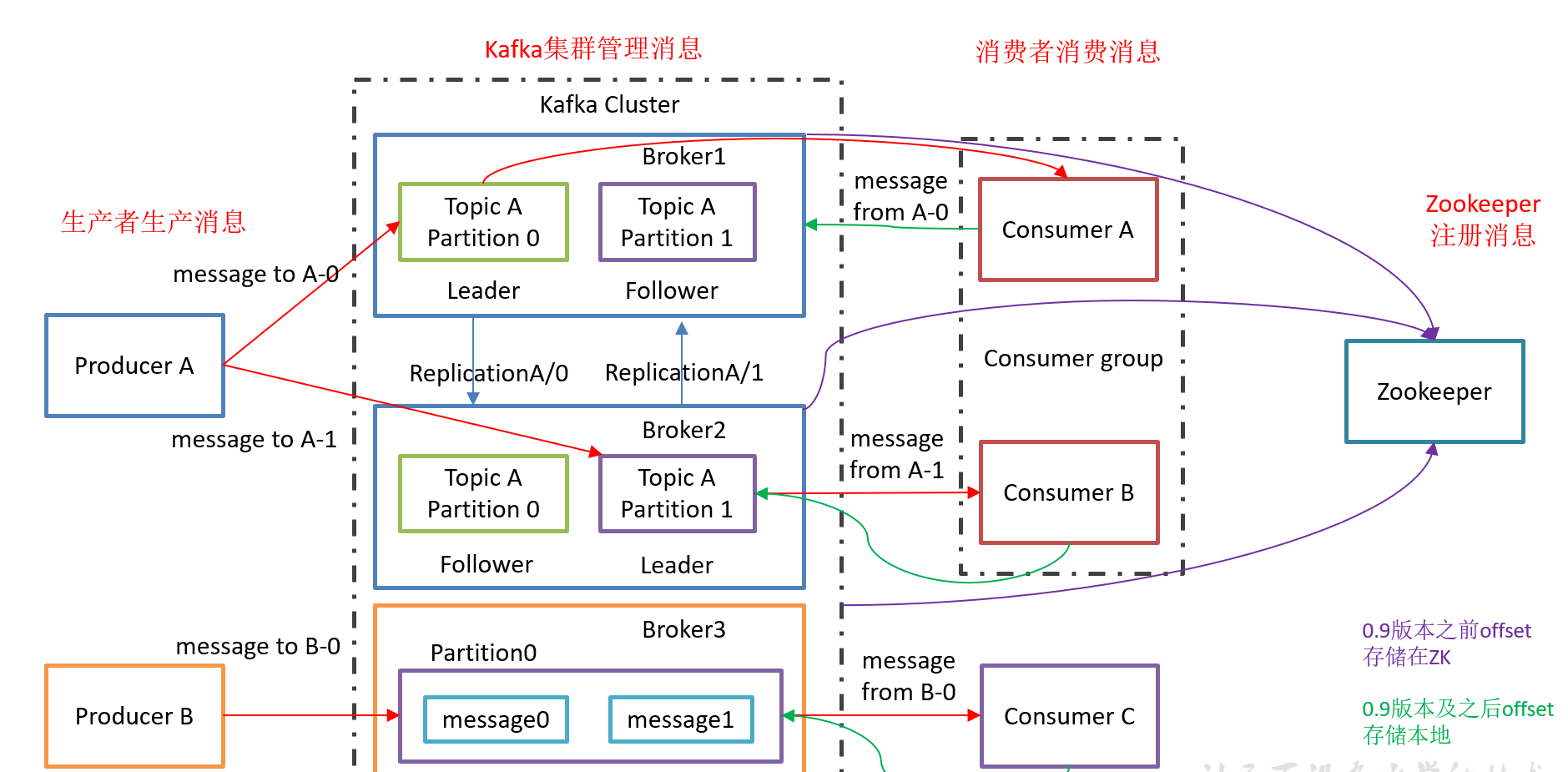
1)Producer :消息生产者,就是向kafka broker发消息的客户端;
2)Consumer :消息消费者,向kafka broker取消息的客户端;
3)Consumer Group (CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic;
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
8)leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
9)follower:每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的leader。
10)kafka集群依赖于zookeeper管理。
2 Kafka安装部署
2.1 集群规划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| zk | zk | zk |
| kafka | kafka | kafka |
2.2 Kafka 下载
http://kafka.apache.org/downloads.html
2.3 集群部署
1)解压安装包
[molly@hadoop102 software]$ tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/2)修改解压后的文件名称
[molly@hadoop102 module]$ mv kafka_2.11-2.4.1.tgz kafka3)在/opt/module/kafka目录下创建logs文件夹
[molly@hadoop102 kafka]$ mkdir logs4)修改配置文件
[molly@hadoop102 kafka]$ cd config/
[molly@hadoop102 config]$ vi server.properties输入以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能,当前版本此配置默认为true,已从配置文件移除
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:21815)配置环境变量
[molly@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[molly@hadoop102 module]$ source /etc/profile6)分发安装包
[molly@hadoop102 module]$ xsync kafka/ 注意:分发之后记得配置其他机器的环境变量
7)分别在hadoop103和hadoop104上修改配置文件/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2
注:broker.id不得重复
8)启动集群
先启动Zookeeper集群,然后启动kafaka
[molly@hadoop102 kafka]$ zk.sh start 依次在hadoop102、hadoop103、hadoop104节点上启动kafka
[molly@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[molly@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[molly@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties9)关闭集群
[molly@hadoop102 kafka]$ bin/kafka-server-stop.sh stop
[molly@hadoop103 kafka]$ bin/kafka-server-stop.sh stop
[molly@hadoop104 kafka]$ bin/kafka-server-stop.sh stop10)kafka群起脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Input Args Error....."
exit
fi
for i in hadoop102 hadoop103 hadoop104
do
case $1 in
start)
echo "==================START $i KAFKA==================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.1/config/server.properties
;;
stop)
echo "==================STOP $i KAFKA==================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-stop.sh stop
;;
*)
echo "Input Args Error....."
exit
;;
esac
done3 Kafka命令行操作
kafka提供了测试脚本kafka-topics.sh用来测试。
1)查看当前服务器中的所有topic
[molly@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --list2)创建topic
[molly@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 --topic first选项说明:
–topic 定义topic名
–replication-factor 定义副本数
–partitions 定义分区数
3)删除topic
[molly@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic first4)发送消息:生产消息– 9092是kafka默认端口
[molly@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello world
>molly molly5)消费消息
[molly@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --topic first
[molly@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic first–from-beginning:会把主题中现有的所有的数据都读取出来。
6)查看某个Topic的详情
[molly@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --describe –-topic first7)修改分区数 alter只能修改
[molly@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --alter –-topic first --partitions 64 Kafka监控
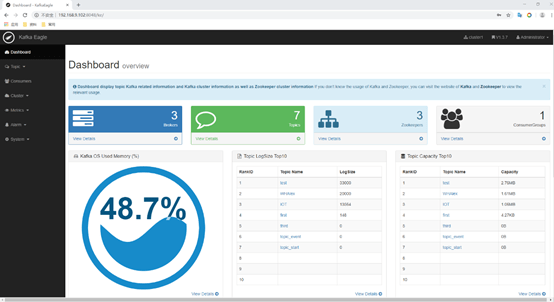
我们知道一个叫kafka manager的kafka管理工具,这个工具管理kafka确实很强大,但是没有安全认证,随便都可以创建,删除,修改topic,而且告警系统,流量波动做的不好。所以,在这里浪尖,再给大家推荐一款kafka 的告警监控管理工具,kafka-eagle。Kafka Eagle是一款开源的Kafka集群监控系统。能够实现broker级常见的JMX监控;能对consumer消费进度进行监控;能在页面上直接对多个集群进行管理;安装方式简单,二进制包解压即用;可以配置告警(钉钉、微信、email均可)。
kafka-eagle主要是有几个我们关注 但kafkamanager不存在的点,值得一提:
- 流量,最长可以查看最近七天的流量波动图
- lag size邮件告警
- 可以用kafkasql分析
相关官方地址:
- 源码: https://github.com/smartloli/kafka-eagle/
- 官网:https://www.kafka-eagle.org/
- 下载: http://download.kafka-eagle.org/
- 安装文档: https://docs.kafka-eagle.org/2.env-and-install
1)修改kafka启动命令
修改kafka-server-start.sh命令中
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi注意:修改之后在启动Kafka之前要分发之其他节点
2)上传压缩包kafka-eagle-bin-1.4.5.tar.gz到集群/opt/software目录
3)解压到本地
[molly@hadoop102 software]$ tar -zxvf kafka-eagle-bin-1.4.5.tar.gz4)进入刚才解压的目录
[molly@hadoop102 kafka-eagle-bin-1.4.5]$ ll
总用量 82932
-rw-rw-r--. 1 molly molly 84920710 8月 13 23:00 kafka-eagle-web-1.4.5-bin.tar.gz5)将kafka-eagle-web-1.3.7-bin.tar.gz解压至/opt/module
[molly@hadoop102 kafka-eagle-bin-1.4.5]$ tar -zxvf kafka-eagle-web-1.4.5-bin.tar.gz -C /opt/module/6)修改名称
[molly@hadoop102 module]$ mv kafka-eagle-web-1.4.5/ eagle7)给启动文件执行权限
[molly@hadoop102 eagle]$ cd bin/
[molly@hadoop102 bin]$ ll
总用量 12
-rw-r--r--. 1 molly molly 1848 8月 22 2017 ke.bat
-rw-r--r--. 1 molly molly 7190 7月 30 20:12 ke.sh
[molly@hadoop102 bin]$ chmod 777 ke.sh8)修改配置文件 conf/system-config.properties
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=false
######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=1234569)添加环境变量
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin
#注意:source /etc/profile10)启动
[atguigu@hadoop102 eagle]$ bin/ke.sh start
... ...
... ...
*******************************************************************
* Kafka Eagle Service has started success.
* Welcome, Now you can visit 'http://192.168.202.102:8048/ke'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> https://www.kafka-eagle.org/ </Usage>
*******************************************************************注意:启动之前需要先启动ZK以及KAFKA
11)登录页面查看监控数据
http://192.168.202.102:8048/ke
5 Flume对接Kafka
5.1 简单实现
1)配置flume
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/data/flume.log
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c12) 启动kafka消费者
3) 进入flume根目录下,启动flume
$ bin/flume-ng agent -c conf/ -n a1 -f jobs/flume-kafka.conf4) 向 /opt/module/data/flume.log里追加数据,查看kafka消费者消费情况
$ echo hello >> /opt/module/data/flume.log5.2 数据分离
0)需求
将flume采集的数据按照不同的类型输入到不同的topic中
将日志数据中带有molly的,输入到Kafka的first主题中,
将日志数据中带有shangguigu的,输入到Kafka的second主题中,
其他的数据输入到Kafka的third主题中
1) 编写Flume的Interceptor
package com.atguigu.kafka.flumeInterceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import javax.swing.text.html.HTMLEditorKit;
import java.util.List;
import java.util.Map;
public class FlumeKafkaInterceptor implements Interceptor {
@Override
public void initialize() {
}
/**
* 如果包含"atguigu"的数据,发送到first主题
* 如果包含"sgg"的数据,发送到second主题
* 其他的数据发送到third主题
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
//1.获取event的header
Map<String, String> headers = event.getHeaders();
//2.获取event的body
String body = new String(event.getBody());
if(body.contains("atguigu")){
headers.put("topic","first");
}else if(body.contains("sgg")){
headers.put("topic","second");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new FlumeKafkaInterceptor();
}
@Override
public void configure(Context context) {
}
}
}2)将写好的interceptor打包上传到Flume安装目录的lib目录下
3)配置flume
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = third
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
#Interceptor
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.kafka.flumeInterceptor.FlumeKafkaInterceptor$MyBuilder
# # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c14) 启动kafka消费者
5) 进入flume根目录下,启动flume
$ bin/flume-ng agent -c conf/ -n a1 -f jobs/flume-kafka.conf6) 向6666端口写数据,查看kafka消费者消费情况