下面我们通过Hive对数据进行操作,主要包括对数据库,表的基本操作和基本函数的使用。
1 Hive数据类型
1.1 基本数据类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
| TINYINT | byte | 1byte有符号整数 | 20 |
| SMALINT | short | 2byte有符号整数 | 20 |
| INT | int | 4byte有符号整数 | 20 |
| BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 时间类型 | ||
| BINARY | 字节数组 |
对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
1.2 集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 | struct() 例如struct<street:string, city:string> |
| MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 | map() 例如map<string, int> |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 | Array() 例如array |
Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
1)案例实操
(1)假设某表有如下一行,我们用JSON格式来表示其数据结构。在Hive下访问的格式为
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 19 ,
"xiaoxiao song": 18
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}(2)基于上述数据结构,我们在Hive里创建对应的表,并导入数据。
创建本地测试文件test.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
注意:MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“_”。
(3)Hive上创建测试表test
create table test(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';字段解释:
row format delimited fields terminated by ‘,’ – 列分隔符
collection items terminated by ‘_’ –MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
map keys terminated by ‘:’ – MAP中的key与value的分隔符
lines terminated by ‘\n’; – 行分隔符
(4)导入文本数据到测试表
load data local inpath ‘/opt/module/hive/datas/test.txt’ into table test;
(5)访问三种集合列里的数据,以下分别是ARRAY,MAP,STRUCT的访问方式
hive (default)> select friends[1],children['xiao song'],address.city from test
where name="songsong";
OK
_c0 _c1 city
lili 18 beijing
Time taken: 0.076 seconds, Fetched: 1 row(s)1.3 类型转化
Hive的原子数据类型是可以进行隐式转换的,类似于Java的类型转换,例如某表达式使用INT类型,TINYINT会自动转换为INT类型,但是Hive不会进行反向转化,例如,某表达式使用TINYINT类型,INT不会自动转换为TINYINT类型,它会返回错误,除非使用CAST操作。
1)隐式类型转换规则如下
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型不可以转换为任何其它的类型。
2)可以使用CAST操作显示进行数据类型转换
例如CAST(‘1’ AS INT)将把字符串’1’ 转换成整数1;如果强制类型转换失败,如执行CAST(‘X’ AS INT),表达式返回空值 NULL。
0: jdbc:hive2://hadoop102:10000> select '1'+2, cast('1'as int) + 2;
+------+------+--+
| _c0 | _c1 |
+------+------+--+
| 3.0 | 3 |
+------+------+--+2 DDL数据定义
2 DDL数据定义
数据库模式定义语言DDL(Data Definition Language),是用于描述数据库中要存储的现实世界实体的语言。具体其实就是对数据库和表的CRUD操作。
2.1 创建数据库
创建数据库语法如下所示:
CREATE DATABASE [IF NOT EXISTS] database_name --数据库名称
[COMMENT database_comment] --数据库备注
[LOCATION hdfs_path] ---数据库存储位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; --DB的一些属性1)创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db。
hive (default)> create datavase mydb;
create table if not exists test1(
id int comment "this is id",
name string comment "this is name"
)
comment "this is table"
row format delimited fields terminated by ','
STORED as textfile
TBLPROPERTIES("createtime=" 2020-4-11");可以在hdfs上看到创建的数据库目录。

2)避免要创建的数据库已经存在错误,增加if not exists判断。(标准写法)
hive (default)> create database db_hive;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database db_hive already exists
hive (default)> create database if not exists db_hive;3)创建一个数据库,指定数据库在HDFS上存放的位置
hive (default)> create database db_hive2 location '/db_hive2.db';2.2 查询数据库
1)显示数据库
hive> show databases;2)显示数据库信息
hive> desc database db_hive;3)显示数据库详细信息,extended
hive> desc database extended db_hive;4)切换当前数据库
hive (default)> use db_hive;2.3 修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。
hive (default)> alter database db_hive set dbproperties('createtime'='20170830');在hive中查看修改结果
hive> desc database extended db_hive;2.4 删除数据库
1)删除空数据库
hive>drop database db_hive2;2)如果删除的数据库不存在,最好采用 if exists判断数据库是否存在
hive> drop database db_hive;
FAILED: SemanticException [Error 10072]: Database does not exist: db_hive
hive> drop database if exists db_hive2;3)如果数据库不为空,可以采用cascade命令,强制删除
hive> drop database db_hive;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
hive> drop database db_hive cascade;2.5 创建表
1)建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name -
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]2)字段解释说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOCATION),在删除表的时候,内部表的元数据和hdfs数据会被一起删除,而外部表只删除元数据,不删除存在hdfs上的数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY创建分区表
(5)CLUSTERED BY创建分桶表
(6)SORTED BY不常用,对桶中的一个或多个列另外排序
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, …)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称, hive使用Serde进行行对象的序列与反序列化。
(8)STORED AS指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
(9)LOCATION :指定表在HDFS上的存储位置。
(10)AS:后跟查询语句,根据查询结果创建表。
(11)LIKE允许用户复制现有的表结构,但是不复制数据。
2.3.1 内部表(管理表)
1)理论
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
(1)普通创建表
create table if not exists student(
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student';(2)根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student2 as select id, name from student;(3)根据已经存在的表结构创建表
create table if not exists student3 like student;(4)查询表的类型
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE 2.3.2 外部表
1)理论
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
2)管理表和外部表的使用场景
每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
3)案例实操
分别创建部门和员工外部表,并向表中导入数据。
(1)上传数据到HDFS
hive (default)> dfs -mkdir /student;
hive (default)> dfs -put /opt/module/datas/student.txt /student;(2)建表语句,创建外部表
创建部门表
create external table if not exists dept(
deptno int,
dname string,
loc int)
row format delimited fields terminated by '\t';(3)查看创建的表
hive (default)>show tables;(4)查看表格式化数据
hive (default)> desc formatted dept;
Table Type: EXTERNAL_TABLE(5)删除外部表
hive (default)> drop table dept;外部表删除后,hdfs中的数据还在,但是metadata中dept的元数据已被删除
2.5.3 管理表与外部表的互相转换
(1)查询表的类型
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE(2)修改内部表student2为外部表
alter table student2 set tblproperties('EXTERNAL'='TRUE');(3)修改外部表student2为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');注意:(‘EXTERNAL’=’TRUE’)和(‘EXTERNAL’=’FALSE’)为固定写法,区分大小写!
2.6 修改表
2.6.1 重命名表
1)语法
ALTER TABLE table_name RENAME TO new_table_name2)实操案例
hive (default)> alter table dept_partition2 rename to dept_partition3;2.6.2 增加/修改/替换列信息
1)语法
(1)更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name](2)增加和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) 注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
2)实操案例
(1)查询表结构
hive> desc dept;(2)添加列
hive (default)> alter table dept add columns(deptdesc string);(3)更新列
hive (default)> alter table dept change column deptdesc desc string;(5)替换列
hive (default)> alter table dept replace columns(deptno string, dname
string, loc string);2.7 删除表
hive (default)> drop table dept;3 DML数据操作
3.1 数据导入
让hdfs的数据和hive表产生关联。上传表数据:hive创建的表其实就是hdfs中的一个目录,所以表数据就映射为hdfs目录下的数据txt。
3.1.1 向表中装载数据(Load)
1)语法
hive> load data [local] inpath ‘数据的path’ [overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
2)实操案例
(0)创建一张表
hive (default)> create table student(id string, name string) row format delimited fields terminated by '\t';(1)加载本地文件到hive
hive (default)> load data local inpath '/opt/module/hive/datas/student.txt' into table default.student;(2)加载HDFS文件到hive中
上传文件到HDFS
hive (default)> dfs -put /opt/module/hive/datas/student.txt /user/molly/hive;加载HDFS上数据
hive (default)> load data inpath '/user/molly/hive/student.txt' into table default.student;(3)加载数据覆盖表中已有的数据
上传文件到HDFS
hive (default)> dfs -put /opt/module/datas/student.txt /user/molly/hive;加载数据覆盖表中已有的数据
hive (default)> load data inpath '/user/molly/hive/student.txt' overwrite into table default.student;3.1.2 通过查询语句向表中插入数据(Insert)
1)创建一张表
hive (default)> create table student_par(id int, name string) row format delimited fields terminated by '\t';2)基本插入数据
hive (default)> insert into table student_par values(1,'wangwu'),(2,'zhaoliu');3)基本模式插入(根据单张表查询结果)
hive (default)> insert overwrite table student_par select id, name from student ; insert into:以追加数据的方式插入到表或分区,原有数据不会删除
insert overwrite:会覆盖表中已存在的数据
注意:insert不支持插入部分字段
4)多表(多分区)插入模式(根据多张表查询结果)
hive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';3.1.3 查询语句中创建表并加载数据(As Select)
根据查询结果创建表(查询的结果会添加到新创建的表中)
hive (default)>create table if not exists student3 as select id, name from student;3.1.4 创建表时通过Location指定加载数据路径—用的多
1)上传数据到hdfs上
hive (default)> dfs -mkdir /student;
hive (default)> dfs -put /opt/module/datas/student.txt /student;2)创建表,并指定在hdfs上的位置
hive (default)> create external table if not exists student5(
id int, name string)
row format delimited fields terminated by '\t'
location '/student;先建表,后指定hdfss数据文件到该表。
hadoop fs -put test.txt /test2.table3)查询数据
hive (default)> select * from student5;3.1.5 Import数据到指定Hive表中
注意:先用export导出后,再将数据导入。
hive (default)> import table student2 from '/user/hive/warehouse/export/student';3.2 数据导出
3.2.1 Insert导出
1)将查询的结果导出到本地(有local)
hive (default)> insert overwrite local directory '/opt/module/hive/datas/export/student'
select * from student;2)将查询的结果格式化导出到本地
hive(default)>insert overwrite local directory '/opt/module/hive/datas/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from student;3)将查询的结果导出到HDFS上(没有local)
hive (default)> insert overwrite directory '/user/molly/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;3.2.2 Hadoop命令导出到本地
hive (default)> dfs -get /user/hive/warehouse/student/student.txt
/opt/module/datas/export/student3.txt;3.2.3 Hive Shell 命令导出
基本语法:(hive -f/-e 执行语句或者脚本 > file)
[molly@hadoop102 hive]$ bin/hive -e 'select * from default.student;' > /opt/module/hive/datas/export/student4.txt;3.2.4 Export导出到HDFS上
hive (default)>export table default.student to '/user/hive/warehouse/export/student';export和import主要用于两个Hadoop平台集群之间Hive表迁移。
3.2.5 清除表中数据(Truncate)
注意:Truncate只能删除管理表,不能删除外部表中数据
hive (default)> truncate table student;4 数据查询—用的很多
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition] -筛选条件
[GROUP BY col_list]---分组
[HAVING having_condition]---分组后的过滤条件
[ORDER BY col_list]—--全局排序
[CLUSTER BY col_list—---分区排序
|
[DISTRIBUTE BY col_list] –---分区排序 类似MR中的分区
[SORT BY col_list] –区内排序
]
[LIMIT number]--限制返回条数HQL查询语法和sql大致相同,这里就不一一列举,这里需要提出说的是排序的用法。
需要知道的是order by是全局排序,针对所有数据进行排序;SORT BY是分区内的排序
4.1 全局排序(Order By)
Order By:全局排序,只有一个Reducer
例如:查询员工信息按工资升序排列
hive (default)> select * from emp order by sal;4.2 每个Reduce内部排序(Sort By)
Sort By:对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用sort by。
Sort by为每个reducer产生一个排序文件(即为分区内的排序)。每个Reducer内部进行排序,对全局结果集来说不是排序。
1)设置reduce个数
hive (default)> set mapreduce.job.reduces=3;2)查看设置reduce个数
hive (default)> set mapreduce.job.reduces;3)根据部门编号降序查看员工信息
hive (default)> select * from emp sort by deptno desc;4)将查询结果导入到文件中(按照部门编号降序排序)
hive (default)> insert overwrite local directory '/opt/module/hive/datas/sortby-result'
select * from emp sort by deptno desc;4.3 分区(Distribute By)
Distribute By: 在有些情况下,我们需要控制某个特定行应该到哪个reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by类似MR中partition(自定义分区),进行分区,结合sort by使用。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
1)案例实操:
(1)先按照部门编号分区,再按照员工编号降序排序。
hive (default)> set mapreduce.job.reduces=3;
hive (default)> insert overwrite local directory '/opt/module/hive/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;注意:
Ø distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一个区。
Ø Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
4.4 Cluster By
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
(1)以下两种写法等价
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。
5 函数使用
5.1 系统内置函数
1)查看系统自带的函数
hive> show functions;2)显示自带的函数的用法
hive> desc function upper;3)详细显示自带的函数的用法
hive> desc function extended upper;5.2 常用内置函数
5.2.1 空字段赋值
1)函数说明
NVL:给值为NULL的数据赋值,它的格式是NVL( value,default_value)。它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL。
2)数据准备:采用员工表
3)查询:如果员工的comm为NULL,则用-1代替
hive (default)> select comm,nvl(comm, -1) from emp;5.2.2 CASE WHEN THEN ELSE END
1)数据准备
| name | dept_id | sex |
|---|---|---|
| 悟空 | A | 男 |
| 大海 | A | 男 |
| 宋宋 | B | 男 |
| 凤姐 | A | 女 |
| 婷姐 | B | 女 |
| 婷婷 | B | 女 |
2)需求
求出不同部门男女各多少人。结果如下:
dept_Id 男 女
A 2 1
B 1 2
3)按需求查询数据
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id;5.2.3 行转列
1)相关函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,…):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
注意: CONCAT_WS must be “string or array
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
COLLECT_list(col): 相比COLLECT_SET就是不去重的操作。
2)数据准备
| name | constellation | blood_type |
|---|---|---|
| 孙悟空 | 白羊座 | A |
| 大海 | 射手座 | A |
| 宋宋 | 白羊座 | B |
| 猪八戒 | 白羊座 | A |
| 凤姐 | 射手座 | A |
| 苍老师 | 白羊座 | B |
3)需求
把星座和血型一样的人归类到一起。结果如下:
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋|苍老师4)创建本地constellation.txt,导入数据
[molly@hadoop102 datas]$ vim person_info.txt
孙悟空 白羊座 A
大海 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
苍老师 白羊座 B5)创建hive表并导入数据
create table person_info(
name string,
constellation string,
blood_type string)
row format delimited fields terminated by "\t";
load data local inpath "/opt/module/hive/datas/person_info.txt" into table person_info;6)按需求查询数据
SELECT t1.c_b , CONCAT_WS("|",collect_set(t1.name))
FROM (
SELECT NAME ,CONCAT_WS(',',constellation,blood_type) c_b
FROM person_info
)t1
GROUP BY t1.c_b5.2.4 列转行
1)函数说明
**EXPLODE(col)**:将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW(侧写表)
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
2)数据准备
表6-7 数据准备
| movie | category |
|---|---|
| 《疑犯追踪》 | 悬疑,动作,科幻,剧情 |
| 《Lie to me》 | 悬疑,警匪,动作,心理,剧情 |
| 《战狼2》 | 战争,动作,灾难 |
3)需求
将电影分类中的数组数据展开。结果如下:
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难4)创建本地movie.txt,导入数据
[molly@hadoop102 datas]$ vi movie_info.txt
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难5)创建hive表并导入数据
create table movie_info(
movie string,
category string)
row format delimited fields terminated by "\t";
load data local inpath "/opt/module/hive/datas/movie_info.txt" into table movie_info;6)按需求查询数据
SELECT movie,category_name
FROM movie_info
lateral VIEW
explode(split(category,",")) movie_info_tmp AS category_name ;5.2.5 窗口函数(开窗函数)
1)相关函数说明
**OVER()**:指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的改变而变化。涉及关键字如下
| CURRENT ROW | 当前行 |
|---|---|
| n PRECEDING | 往前n行数据 |
| n FOLLOWING | 往后n行数据 |
| UNBOUNDED | 起点 |
| UNBOUNDED PRECEDING | 表示从前面的起点 |
| UNBOUNDED FOLLOWING | 表示到后面的终点 |
| LAG(col,n,default_val) | 往前第n行数据 |
| LEAD(col,n, default_val) | 往后第n行数据 |
| NTILE(n) | 把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型 |
总结如下:
OVER() 默认为每条数据都开一个窗口,窗口大小是当前数据集的大小。
OVER(partition by…. ) 会按照指定字段进行分区,将分区字段的值仙童的数据划分到相同的区;每个区中的每条数据都会开启一个窗口,每条数据的窗口大小默认为当前分区数据的大小。
OVER(order by …) 会在窗口中按照指定的字段对数据进行排序,会为每条数据都开启一个窗口,默认窗口大小为从数据集开始到当前行。
**OVER(partition by …order by..)**:会按照指定的字段进行分区,将分区字段的值仙童的数据划分到相同的区,在每个区会按照指定字段进行排序;每个区中的每条数据都会开启一个窗口,每条数据的窗口大小默认为当前分区中从数据集开始到当前行。相当于:partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row
关键字总结
| Order by | 全局排序;窗口函数中排序 |
|---|---|
| Distribute by | 分区 |
| Sort by | 区内排序 |
| Cluster by | 分区排序 |
| Partition by | 窗口函数中分区 |
| Partitioned by | 建表 指定分区字段 |
| Clustered by | 建表 指定分桶字段 |
注意partition by …order by组合;Distribute by和Sort by 组合使用
2)数据准备:name,orderdate,cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,943)需求
(1)查询在2017年4月份购买过的顾客及总人数
(2)查询顾客的购买明细及月购买总额
(3)上述的场景, 将每个顾客的cost按照日期进行累加
(4)查询每个顾客上次的购买时间
(5)查询前20%时间的订单信息
4)创建本地business.txt,导入数据
[molly@hadoop102 datas]$ vi business.txt5)创建hive表并导入数据
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath "/opt/module/hive/datas/business.txt" into table business;6)按需求查询数据
(1) 查询在2017年4月份购买过的顾客及总人数
select name,count(*) over ()
from business
where substring(orderdate,1,7) = '2017-04'
group by name;(2) 查询顾客的购买明细及所有顾客的月购买总额
使用分区:按照每个月做分区
sum(cost) over(partition by month(orderdate)):表示对某个月的所有顾客的购买总额求sum;当前over的窗口大小是分区大小。
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from
business;(3) 将每个顾客的cost按照日期进行累加
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
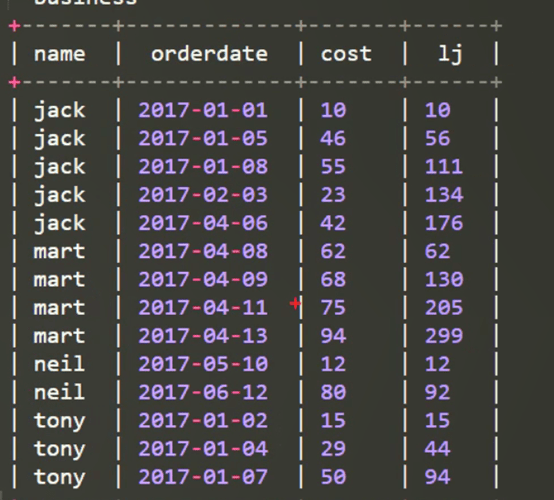
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加 rows必须跟在Order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数据行数量
sample3的执行结果如下:
拓展:数据窗口大小变化
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from business;(4) 查看顾客上次的购买时间和下一次购买时间:使用lag和lead函数
select name,orderdate,cost,
lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as p_ orderdate, lead(orderdate,1,'9999-01-01') over (partition by name order by orderdate) as p_ orderdate
from business; 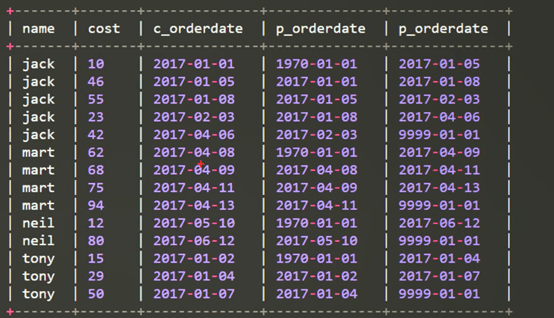
(5) 查询前20%时间的订单信息,使用NTILE函数进行分组。按照时间排序分成5组,取第一个组,即前20%
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) gid
from business
) t
where t. gid = 1; 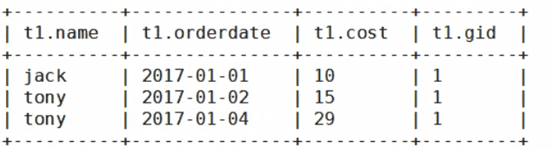
5.2.6 Rank
1)函数说明
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
2)数据准备
| name | subject | score |
|---|---|---|
| 孙悟空 | 语文 | 87 |
| 孙悟空 | 数学 | 95 |
| 孙悟空 | 英语 | 68 |
| 大海 | 语文 | 94 |
| 大海 | 数学 | 56 |
| 大海 | 英语 | 84 |
| 宋宋 | 语文 | 64 |
| 宋宋 | 数学 | 86 |
| 宋宋 | 英语 | 84 |
| 婷婷 | 语文 | 65 |
| 婷婷 | 数学 | 85 |
| 婷婷 | 英语 | 78 |
3)需求
计算每门学科成绩排名。
4)创建本地score.txt,导入数据
[molly@hadoop102 datas]$ vi score.txt5)创建hive表并导入数据
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/hive/datas/score.txt' into table score;6)按需求查询数据
select name,subject,score,rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;查询结果如下面所示:
name subject score rp drp rmp
孙悟空 数学 95 1 1 1
宋宋 数学 86 2 2 2
婷婷 数学 85 3 3 3
大海 数学 56 4 4 4
宋宋 英语 84 1 1 1
大海 英语 84 1 1 2
婷婷 英语 78 3 2 3
孙悟空 英语 68 4 3 4
大海 语文 94 1 1 1
孙悟空 语文 87 2 2 2
婷婷 语文 65 3 3 3
宋宋 语文 64 4 4 4