1 HBase简介
1.1 HBase定义
HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。HBase底层是HDFS。用于实时处理场景。
1.2 HBase数据模型
逻辑上,HBase的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K-V)来看,HBase更像是一个multi-dimensional map。
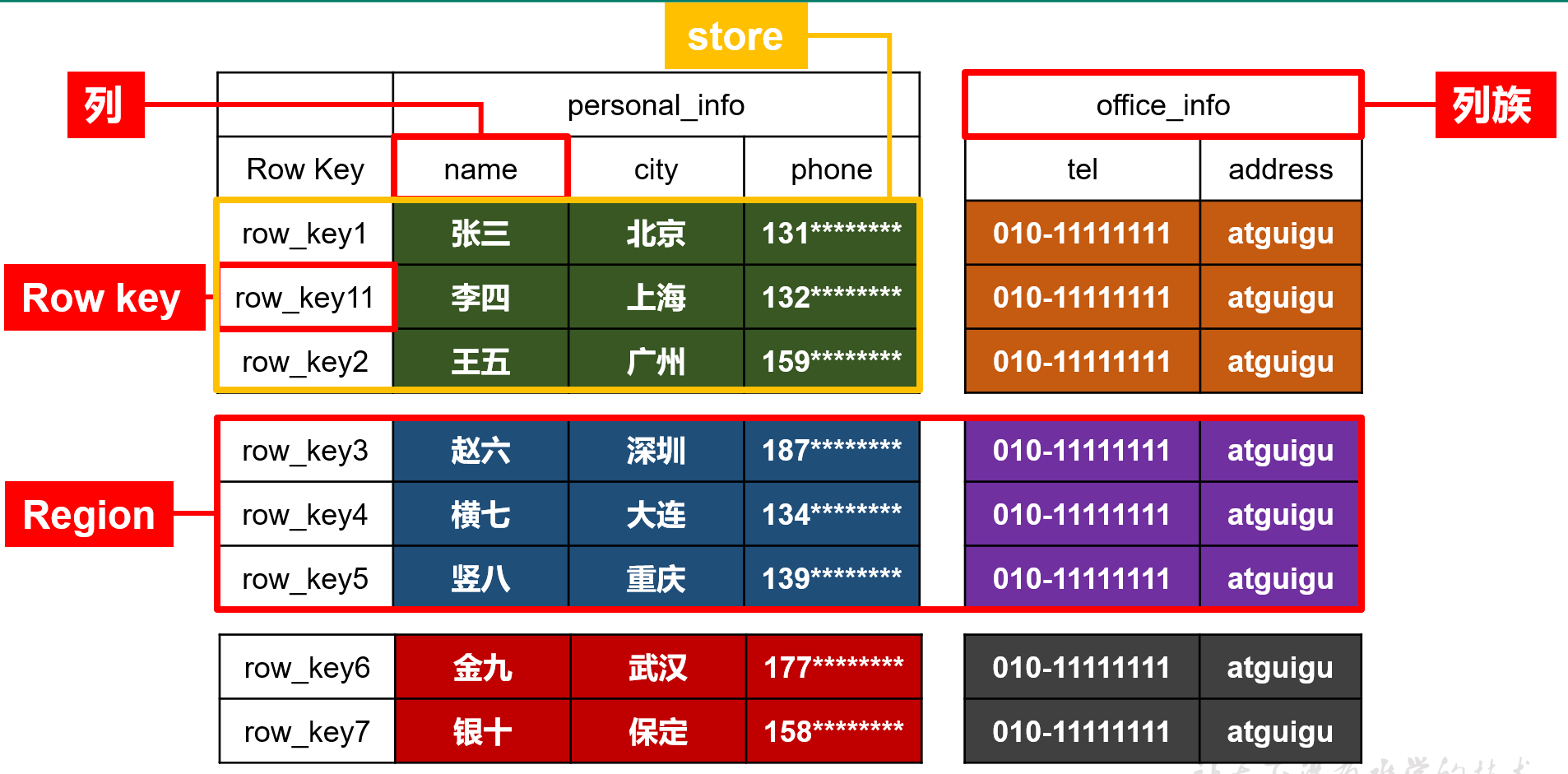
1.2.1 HBase逻辑结构
再HBase中列不能单独存在,必须属于某个列族。一个列族有多个列。
Row key:行键 唯一性 自动排序(字典排序)。
region:分区,表横向切开 去维护。一个Region是存到一起的,即存到同一个机器中。
store: 按照列族去切割,一个store存到一个文件中。
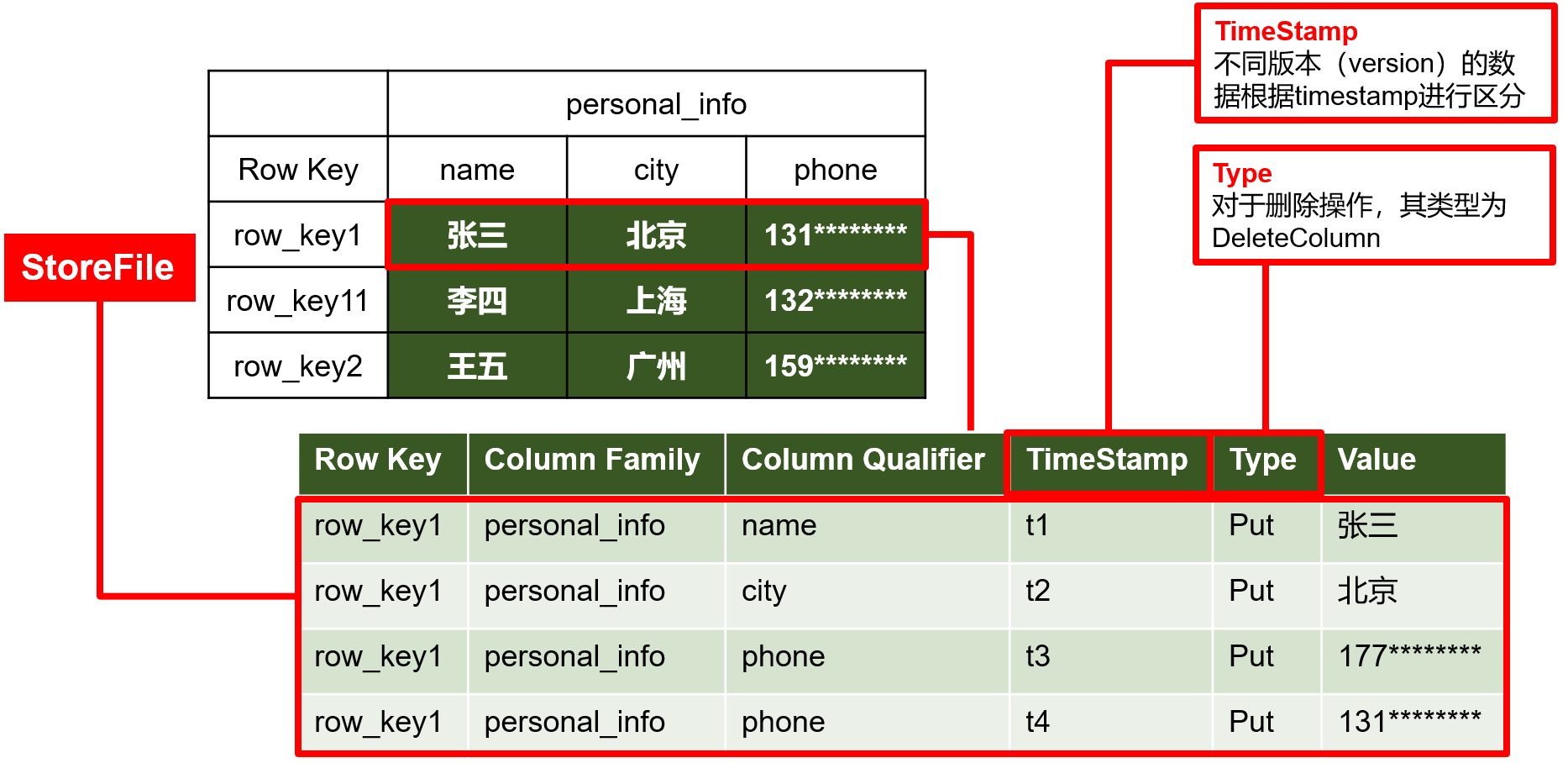
1.2.2 HBase物理存储结构(底层真实存储)
物理存储(真实存储的结构)其实是以KV进行存储,并存储在HDFS中,例如第一条数据:

通过时间戳TimeStamp去标识不同版本,因为HBase不能修改,因此,修改一条数据就是通过追加一条新数据,但是加一个新的时间戳。因此显示的时候,显示时间戳最大的数据即可。过期的数据会按照一定的机制去删除。
因此Hbase修改和新增的Type都是PUT。删除的Type是deletecolumn。
1.2.3 数据模型
1)Name Space
命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。
2)Table
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
3)Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要(如果根据其他列去查询例如名字,就会全表扫描,因此效率很低,通常不会使用)。
4)Column
HBase中的每个列都由Column Family(列族)**和Column Qualifier(列限定符)**进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间。
6)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell中的数据全部是字节码形式存贮。
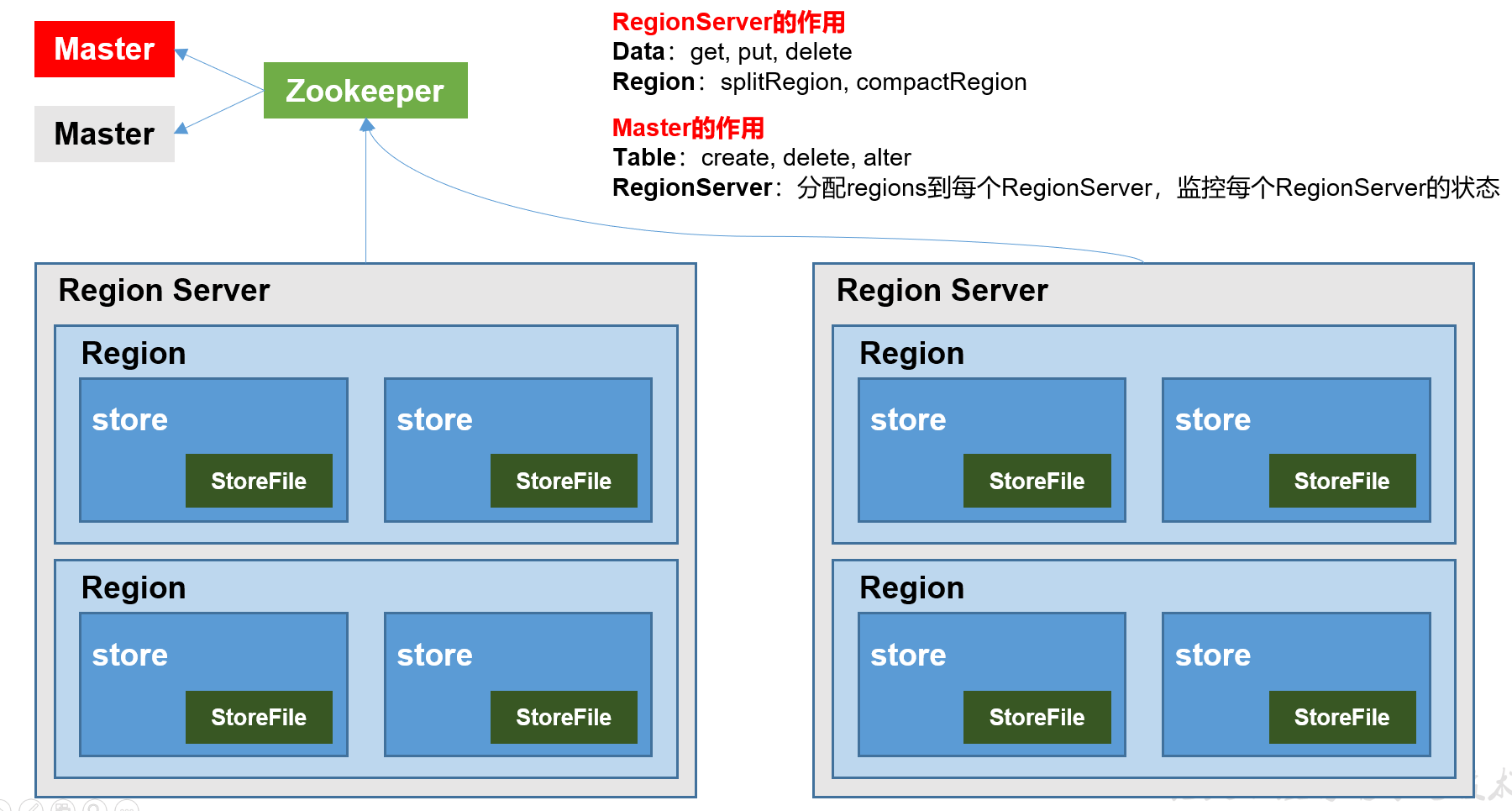
1.3 HBase基本架构(不完整版本)
架构角色:
1)Region Server
Region Server为 Region的管理者,其实现类为HRegionServer,主要作用如下:
对于数据的操作:get, put, delete;(查询修改删除)
对于Region的操作:splitRegion(切分)、compactRegion(合并storeFile)。
2)Master
Master是所有Region Server的管理者,其实现类为HMaster,主要作用如下:
对于表的操作:create, delete, alter(涉及元数据的管理)
对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
3)Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
4)HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用的支持。
2 HBase安装部署
2.1 HBase的解压
解压Hbase到指定目录:
[molly@hadoop102 software]$ tar -zxvf hbase-2.0.5-bin.tar.gz -C /opt/module
[molly@hadoop102 software]$ mv /opt/module/hbase-2.0.5 /opt/module/hbase配置环境变量
[molly@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
#添加
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin2.2 HBase的配置文件
修改HBase对应的配置文件。
1)hbase-env.sh修改内容:
不要使用内置的ZK。
export HBASE_MANAGES_ZK=false2)hbase-site.xml修改内容:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
</configuration>3)regionservers:类似于workers
vim regionservers
hadoop102
hadoop103
hadoop1042.3 HBase远程发送到其他集群
[molly@hadoop102 module]$ xsync hbase/2.4 Zookeeper正常部署
首先保证Zookeeper集群的正常部署,并启动之:
[molly@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[molly@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[molly@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start2.5Hadoop正常部署
Hadoop集群的正常部署并启动:
[molly@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[molly@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh2.6 HBase服务的启动
2.6.1 单点启动
[molly@hadoop102 hbase]$ bin/hbase-daemon.sh start master
[molly@hadoop102 hbase]$ bin/hbase-daemon.sh start regionserver提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
修复提示:错误提示如下所示:
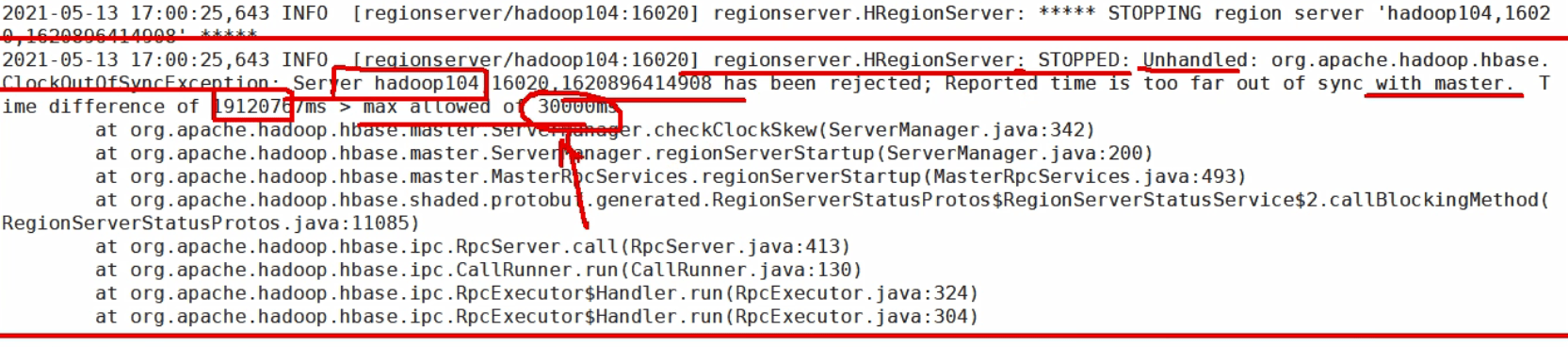
a、同步时间服务
将几台机器进行时间同步操作。
b、属性:hbase.master.maxclockskew设置更大的值
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
<description>Time difference of regionserver from master</description>
</property>2.6.2 群启
[molly@hadoop102 hbase]$ bin/start-hbase.sh对应的停止服务:
[molly@hadoop102 hbase]$ bin/stop-hbase.sh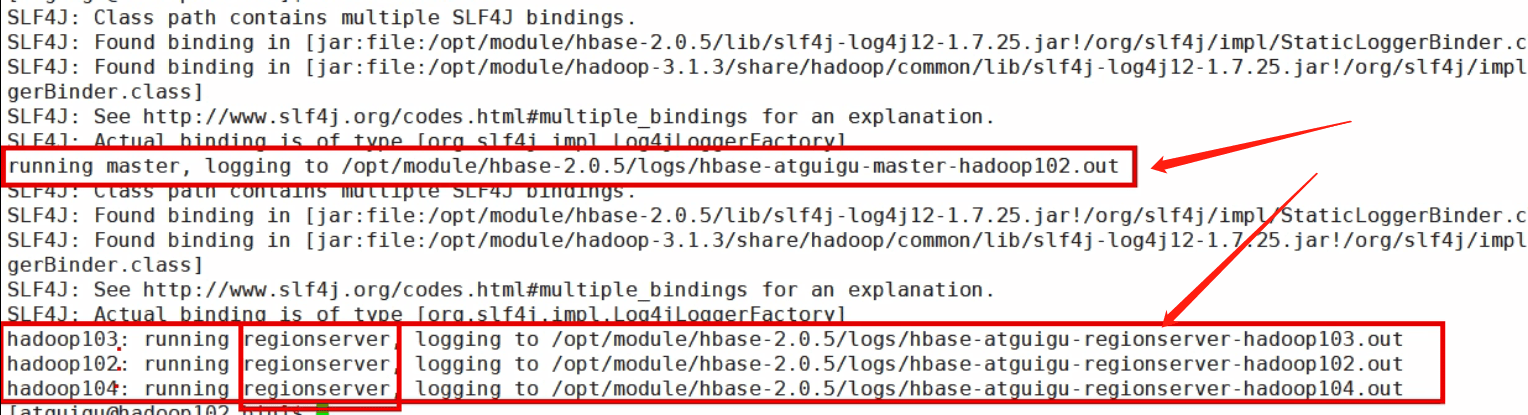
可以看到在那台机器去启用Hbase,那台就是HMaster,这里可以看到102是HMaster
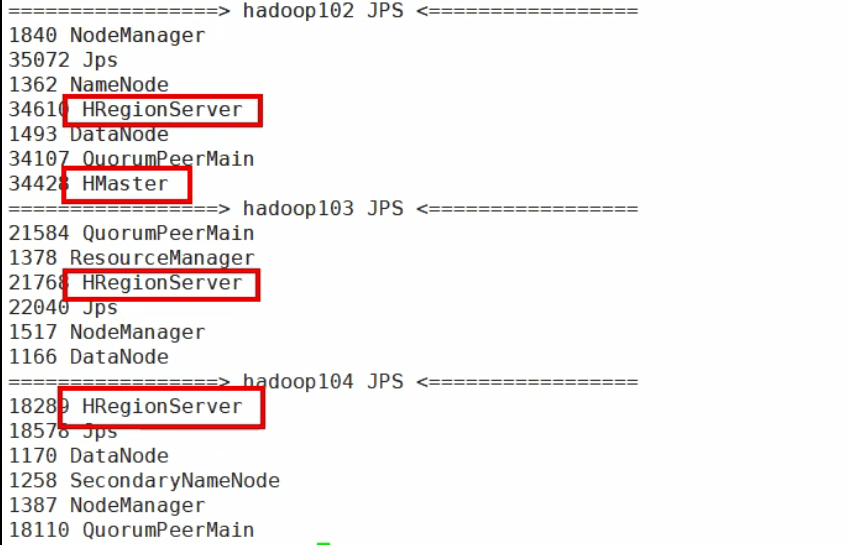
查看ZK:

2.7 查看HBase页面
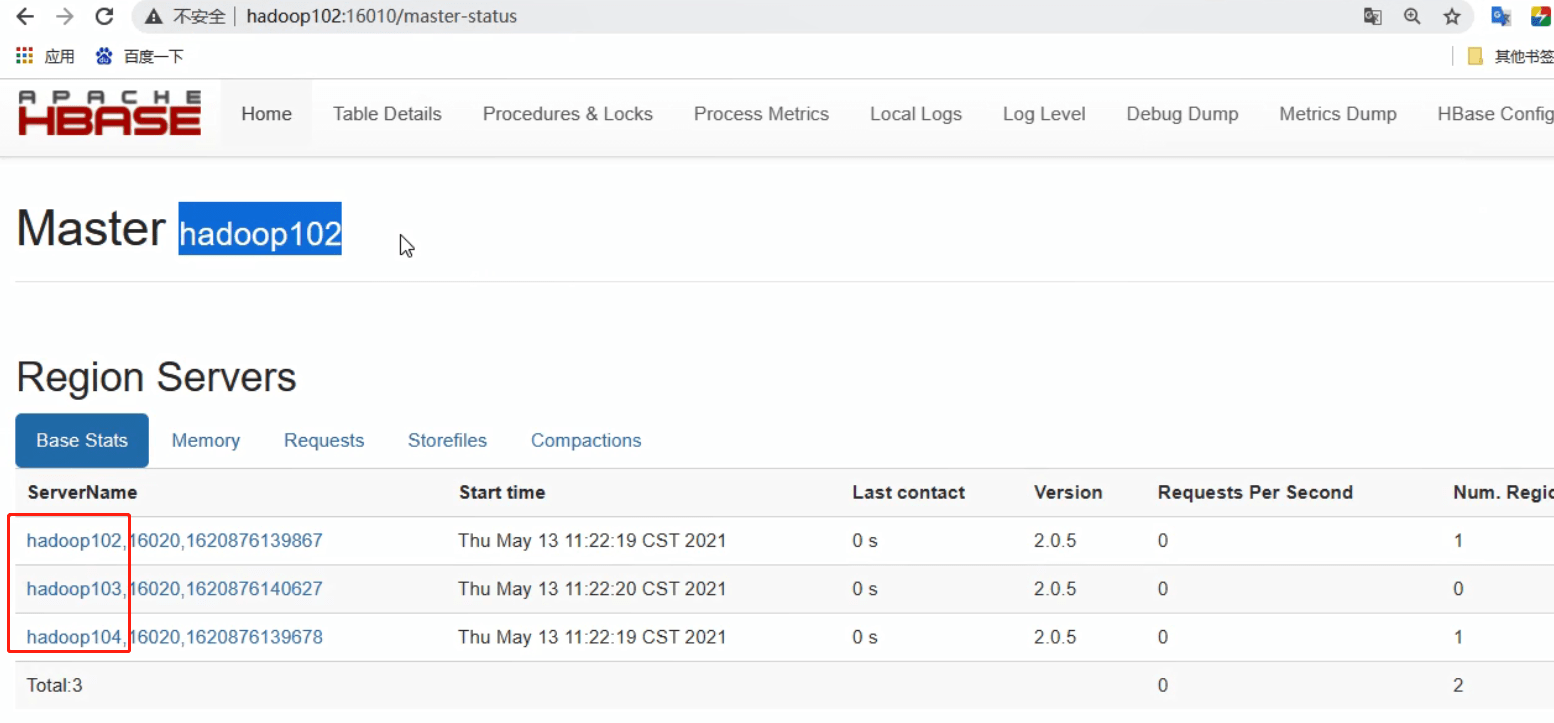
启动成功后,可以通过“host:port”的方式来访问HBase管理页面,例如:
http://hadoop102:16010 可以看到有3个region server
2.8 高可用(可选)
在HBase中HMaster负责监控HRegionServer的生命周期,均衡RegionServer的负载,如果HMaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对HMaster的高可用配置。
1)关闭HBase集群(如果没有开启则跳过此步)
[molly@hadoop102 hbase]$ bin/stop-hbase.sh2)在conf目录下创建backup-masters文件
[molly@hadoop102 hbase]$ touch conf/backup-masters3)在backup-masters文件中配置高可用HMaster节点
[molly@hadoop102 hbase]$ echo hadoop103 > conf/backup-masters4)将整个conf目录scp到其他节点
[molly@hadoop102 hbase]$ scp -r conf/ hadoop103:/opt/module/hbase/
[molly@hadoop102 hbase]$ scp -r conf/ hadoop104:/opt/module/hbase/5)打开页面测试查看
3 HBase Shell操作
3.1 基本操作
1)进入HBase客户端命令行
[molly@hadoop102 hbase]$ bin/hbase shell2)查看帮助命令
hbase(main):001:0> help 3.2 namespace的操作
1)查看当前Hbase中有哪些namespace
hbase(main):002:0> list_namespaceNAMESPACE
default(创建表时未指定命名空间的话默认在default下)
hbase(系统使用的,用来存放系统相关的元数据信息等,勿随便操作)
2)创建namespace
hbase(main):010:0> create_namespace "test"
hbase(main):010:0> create_namespace "test01", {"author"=>"wyh", "create_time"=>"2020-03-10 08:08:08"}3)查看namespace
hbase(main):010:0> describe_namespace "test01"4)修改namespace的信息(添加或者修改属性)
hbase(main):010:0> alter_namespace "test01", {METHOD => 'set', 'author' => 'weiyunhui'}添加或者修改属性:
alter_namespace 'ns1', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'} 删除属性:
alter_namespace 'ns1', {METHOD => 'unset', NAME => ' PROPERTY_NAME '} 5)删除namespace
hbase(main):010:0> drop_namespace "test01"注意: 要删除的namespace必须是空的,其下没有表。
3.3 表的操作
0)查看当前数据库中有哪些表
hbase(main):002:0> list1)创建表
创建student表,列族info
hbase(main):002:0> create 'student','info'2)插入数据到表
表明,rowkey,列,value
hbase(main):003:0> put 'student','1001','info:sex','male'
hbase(main):004:0> put 'student','1001','info:age','18'
hbase(main):005:0> put 'student','1002','info:name','Janna'
hbase(main):006:0> put 'student','1002','info:sex','female'
hbase(main):007:0> put 'student','1002','info:age','20'3)扫描查看表数据
hbase(main):008:0> scan 'student'
hbase(main):009:0> scan 'student',{STARTROW => '1001', STOPROW => '1001'}
hbase(main):010:0> scan 'student',{STARTROW => '1001'}4)查看表结构
hbase(main):011:0> describe 'student'5)更新指定字段的数据
hbase(main):012:0> put 'student','1001','info:name','Nick'
hbase(main):013:0> put 'student','1001','info:age','100'6)查看“指定行”或“指定列族:列”的数据必须:指定rowkey
hbase(main):014:0> get 'student','1001'
hbase(main):015:0> get 'student','1001','info:name'
hbase(main):015:0> get 'student','1001','info:name','info:age'7)统计表数据行数
hbase(main):021:0> count 'student'8)删除数据
删除某rowkey的全部数据:
hbase(main):016:0> deleteall 'student','1001'删除某rowkey的某一列数据:
hbase(main):017:0> delete 'student','1002','info:sex'9)清空表数据
hbase(main):018:0> truncate 'student'提示:清空表的操作顺序为先disable,然后再truncate。
10)删除表
首先需要先让该表为disable状态:
hbase(main):019:0> disable 'student'然后才能drop这个表:
hbase(main):020:0> drop 'student'提示:如果直接drop表,会报错:ERROR: Table student is enabled. Disable it first.
11)变更表信息
将info列族中的数据存放3个版本:
hbase(main):022:0> alter 'student',{NAME=>'info',VERSIONS=>3}
hbase(main):022:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3}