1 HBase架构解析
1.1 RegionServer 架构
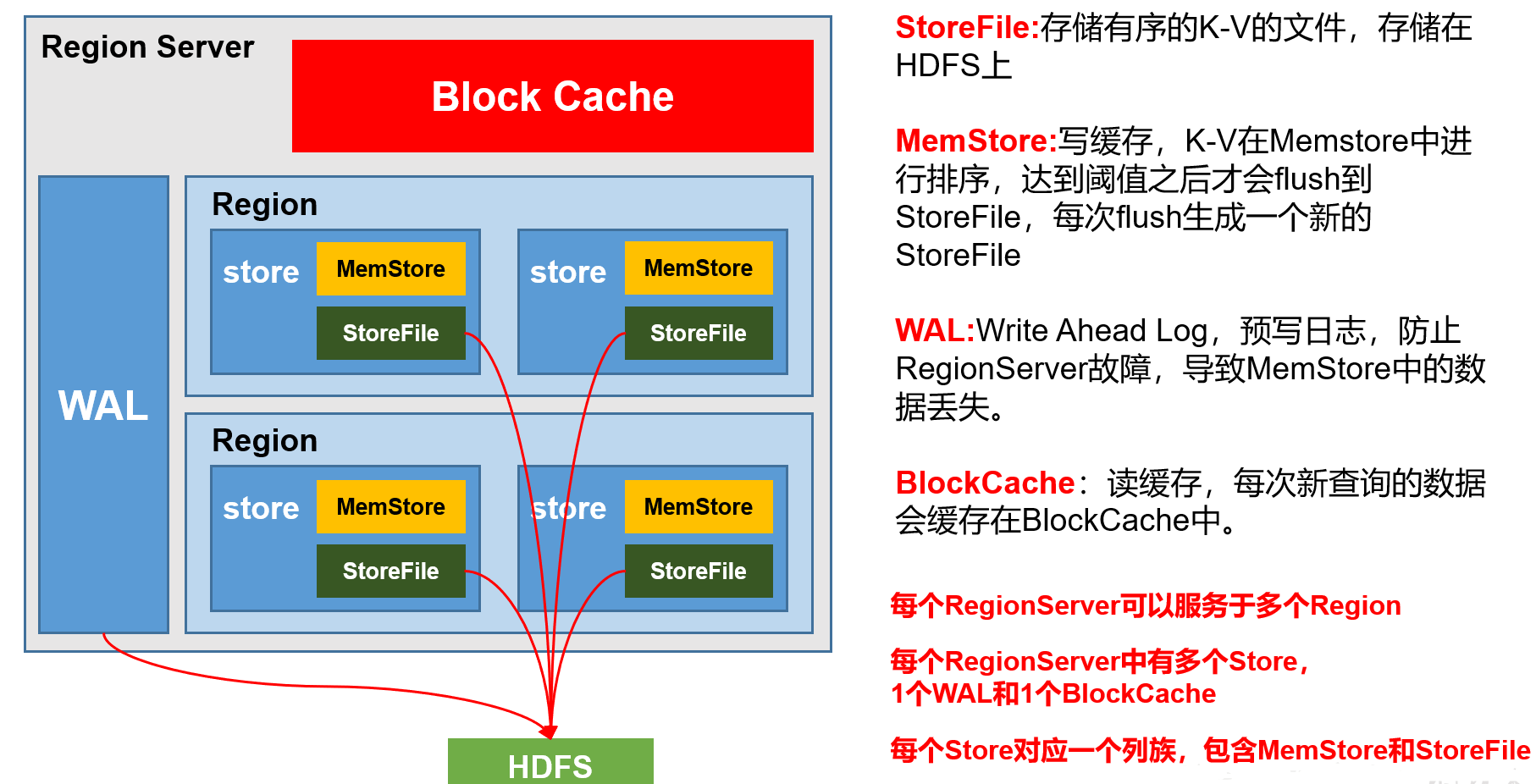
1)StoreFile
保存实际数据的物理文件,StoreFile以Hfile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
2)MemStore
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
3)WAL
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)BlockCache
读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询(LRU机制清理)。
1.2 写流程
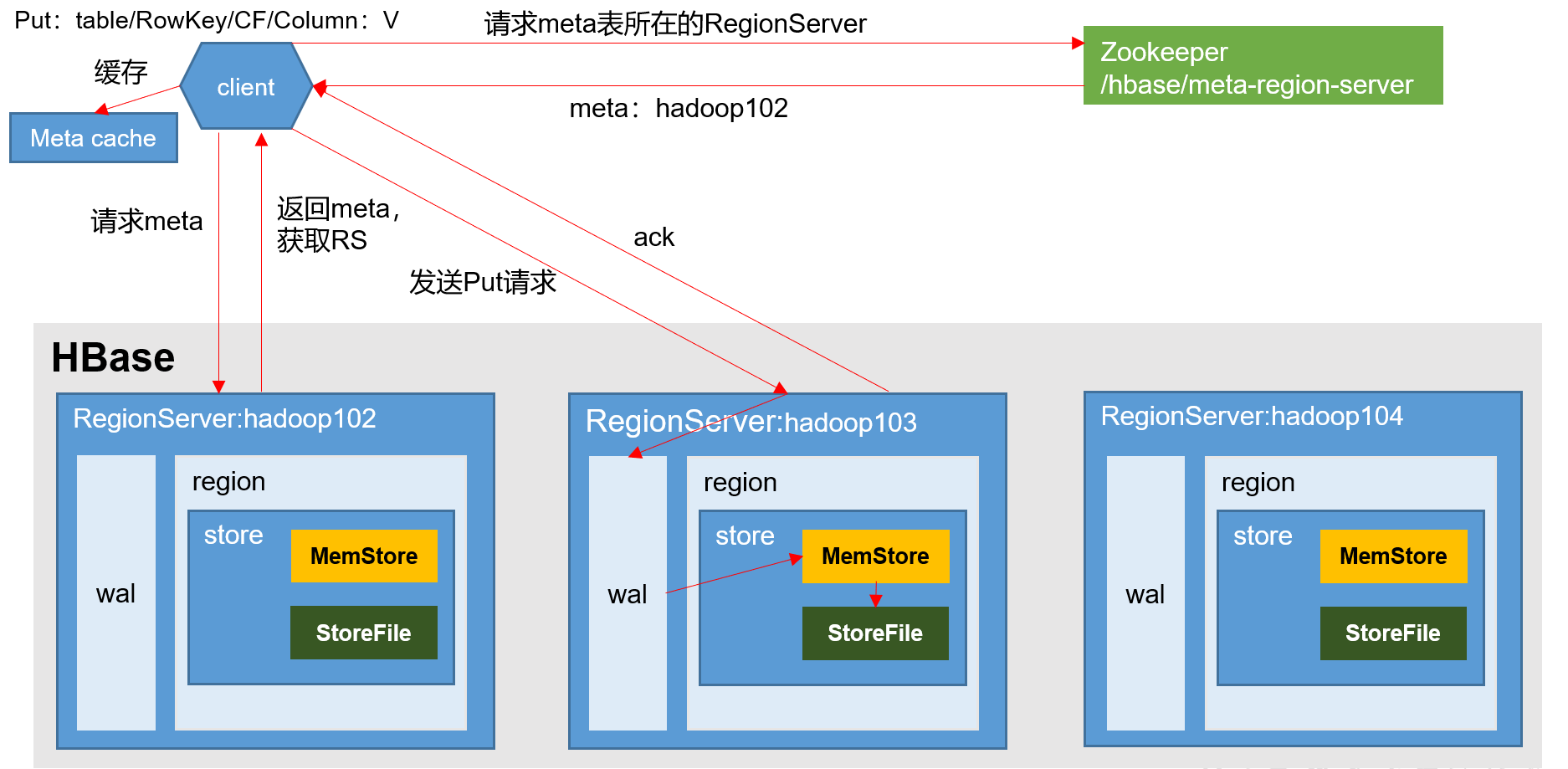
写流程:
1)Client先访问zookeeper,获取hbase:meta(存储业务表的元数据)表位于哪个Region Server。可以看到hbase:meta表存在hadoop104中。

2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。途中发现:该表是存储在hadoop103的(scan ‘student’)。

3)与目标Region Server进行通讯;
4)将数据顺序写入(追加)到WAL;
5)将数据写入对应的MemStore,数据会在MemStore进行排序;
6)向客户端发送ack;
7)等达到MemStore的刷写时机后,将数据刷写到HFile。
1.3 MemStore Flush
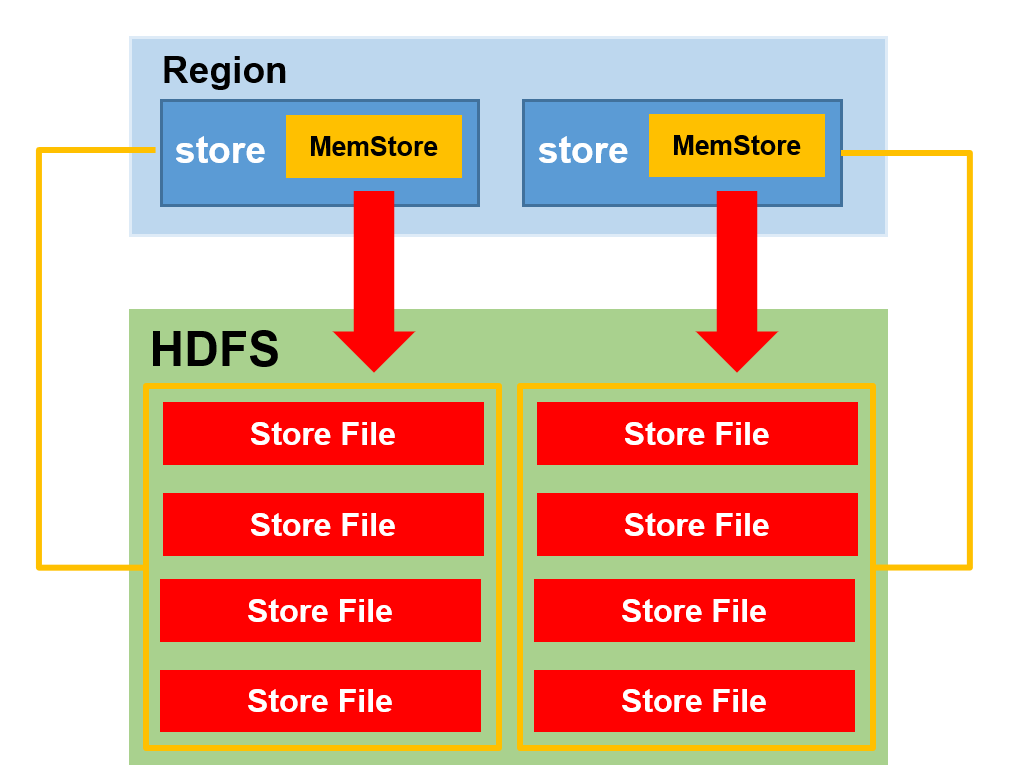
MemStore刷写时机:
0)手动刷写 :刷写’stu’表
flush 'stu'1)当某个memstore的大小达到了hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写。
当memstore的大小达到了
hbase.hregion.memstore.flush.size(默认值128M)* hbase.hregion.memstore.block.multiplier(默认值4)时,会阻止继续往该memstore写数据。
2)当region server中memstore的总大小达到
java_heapsize*hbase.regionserver.global.memstore.size(默认值0.4)*hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下。
当region server中memstore的总大小达到
java_heapsize*hbase.regionserver.global.memstore.size(默认值0.4)时,会阻止继续往所有的memstore写数据。
- 到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认1小时)。
4)当WAL文件的数量超过hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.logs以下(该属性名已经废弃,现无需手动设置,最大值为32)。
1.4 读流程
1.4.1 整体流程
和写的流程是一样的。
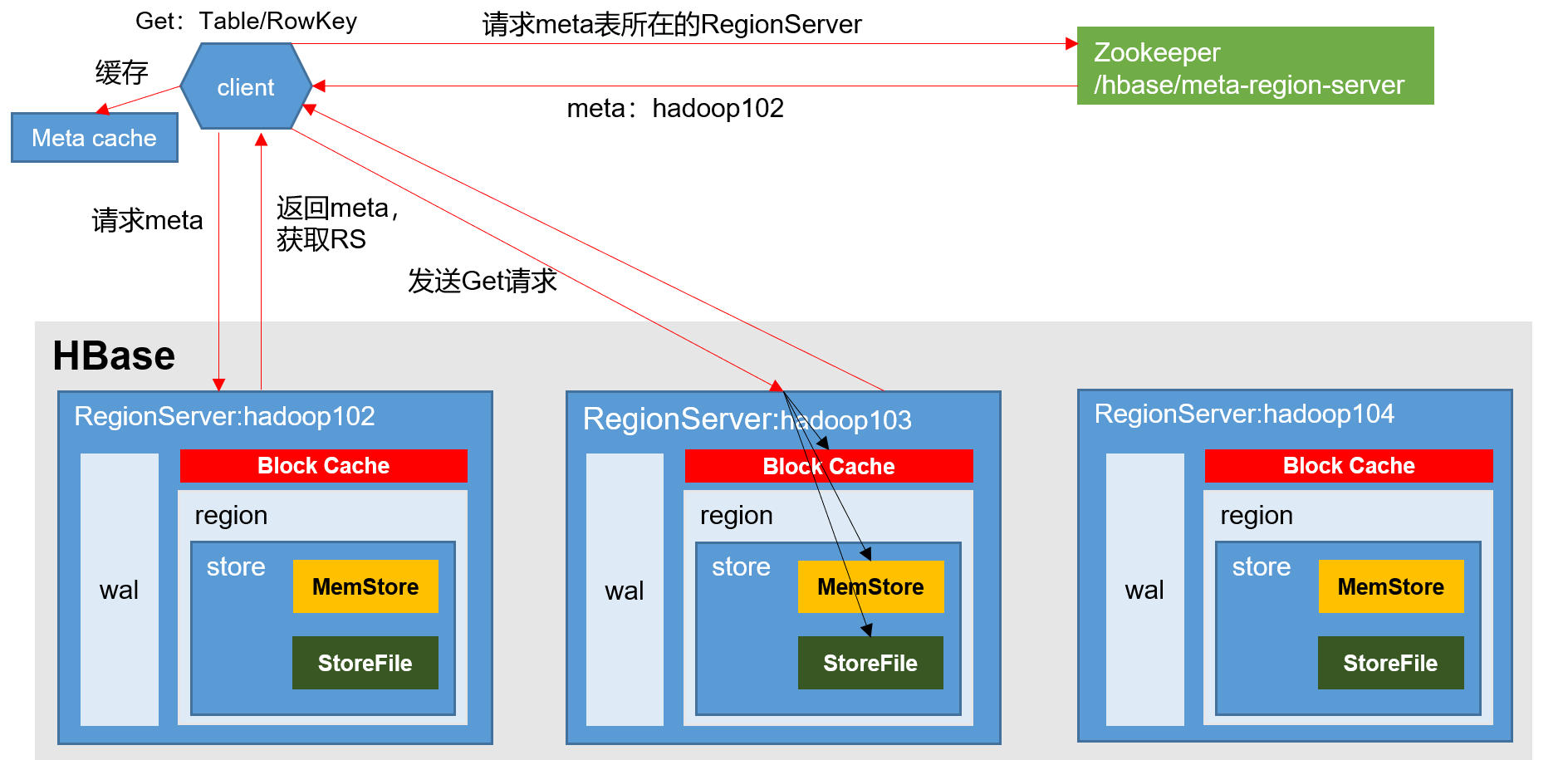
1.4.2 Merge细节
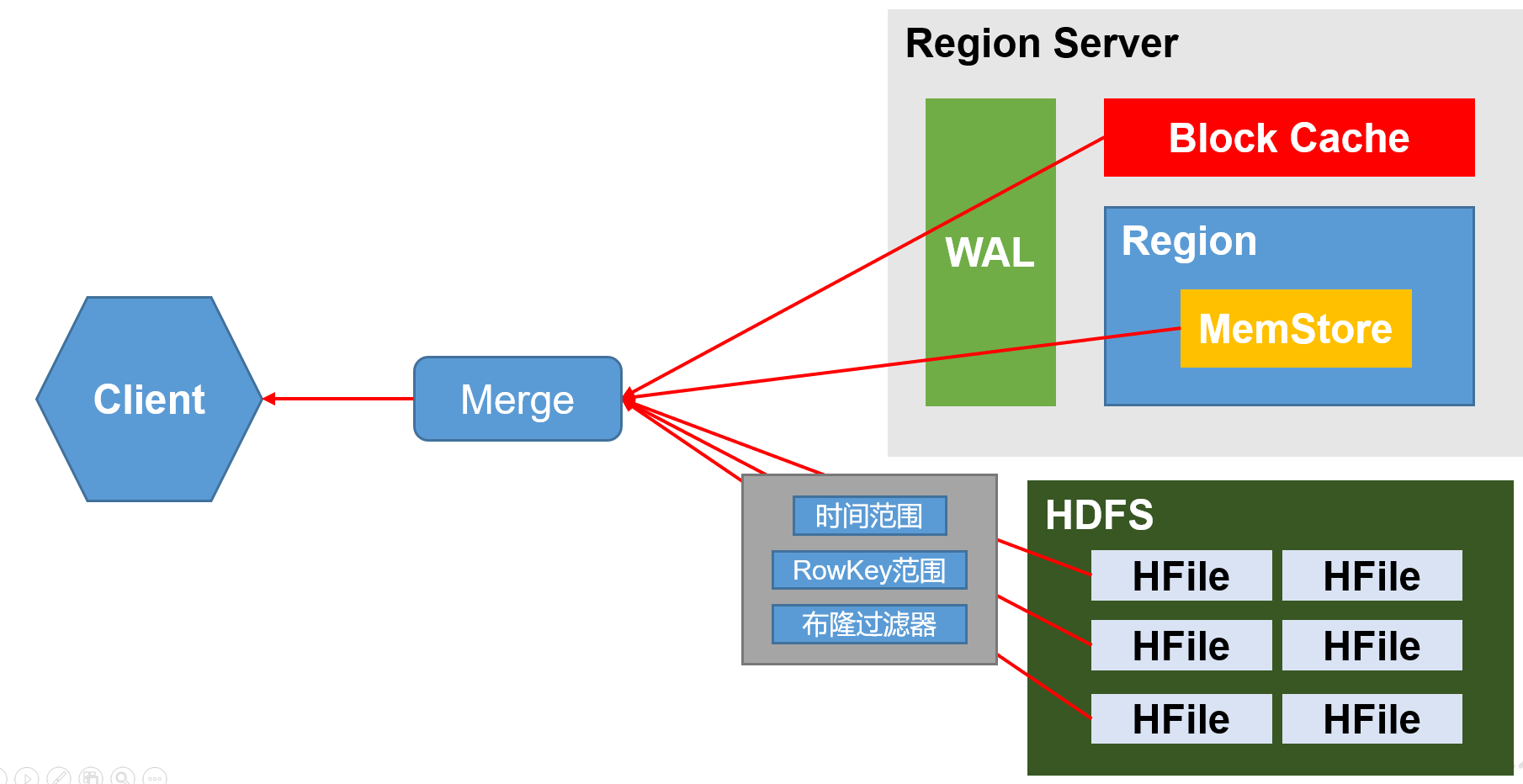
读流程
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标Region Server进行通讯;
4)分别在MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
5)将查询到的新的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。
6)将合并后的最终结果返回给客户端。
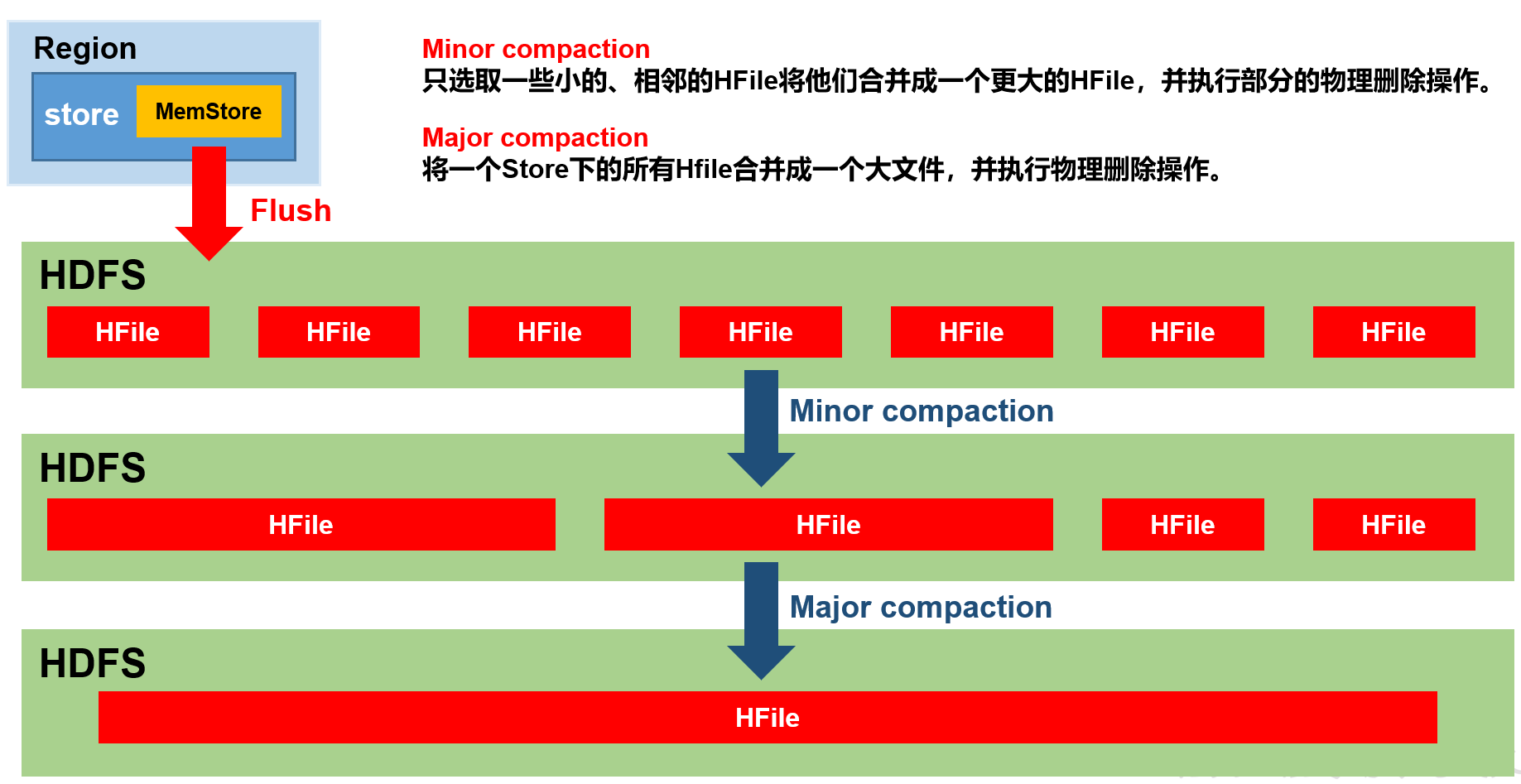
1.5 StoreFile Compaction
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Compaction分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据。
1.6 Region Split
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
Region Split时机:
1)当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize,该Region就会进行拆分(0.94版本之前)。
2)当1个region中的某个Store下所有StoreFile的总大小超过*Min(initialSize x R^3 ,hbase.hregion.max.filesize”)**,该Region就会进行拆分。其中initialSize的默认值为2hbase.hregion.memstore.flush.size,R为当前Region Server中属于该Table的Region个数(0.94版本之后)。
具体的切分策略为:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了。
3)Hbase 2.0引入了新的split策略:如果当前RegionServer上该表只有一个Region,按照2 * hbase.hregion.memstore.flush.size分裂,否则按照hbase.hregion.max.filesize分裂。

2 HBase优化
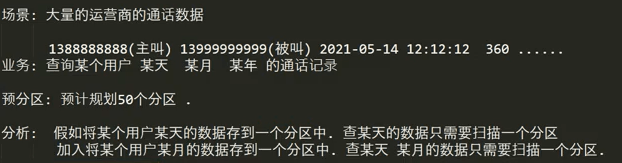
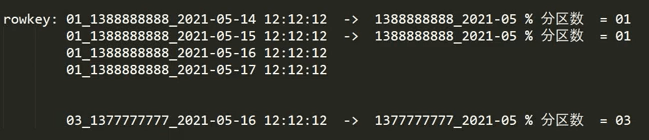
2.1 预分区(region)
建表的时候就设计好几个分区。
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。
1)手动设定预分区
hbase> create 'staff1','info',SPLITS => ['1000','2000','3000','4000']2)生成16进制序列预分区
create 'staff2','info',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}3)按照文件中设置的规则预分区
创建splits.txt文件内容如下:
aaaa
bbbb
cccc
dddd然后执行:
create 'staff3','info',SPLITS_FILE => 'splits.txt'4)使用JavaAPI创建预分区
//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = 某个散列值函数
//创建HbaseAdmin实例
HBaseAdmin hAdmin = new HBaseAdmin(HbaseConfiguration.create());
//创建HTableDescriptor实例
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
//通过HTableDescriptor实例和散列值二维数组创建带有预分区的Hbase表
hAdmin.createTable(tableDesc, splitKeys);2.2 RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。接下来我们就谈一谈rowkey常用的设计方案。
1)生成随机数、hash、散列值
比如:
原本rowKey为1001的,SHA1后变成:dd01903921ea24941c26a48f2cec24e0bb0e8cc7
原本rowKey为3001的,SHA1后变成:49042c54de64a1e9bf0b33e00245660ef92dc7bd
原本rowKey为5001的,SHA1后变成:7b61dec07e02c188790670af43e717f0f46e8913
在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的rowKey来Hash后作为每个分区的临界值。
2)字符串反转
20170524000001转成10000042507102
20170524000002转成20000042507102
这样也可以在一定程度上散列逐步put进来的数据。
3)字符串拼接
20170524000001_a12e
20170524000001_93i7
rowkey设计原则:
唯一性 散列性 长度

2.3 内存优化
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~36G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
2.4 基础优化
1)Zookeeper会话超时时间
hbase-site.xml
属性:zookeeper.session.timeout
解释:默认值为90000毫秒(90s)。当某个RegionServer挂掉,90s之后Master才能察觉到。可适当减小此值,以加快Master响应,可调整至60000毫秒。
2)设置RPC监听数量
hbase-site.xml
属性:zookeeper.session.timeout
解释:默认值为90000毫秒(90s)。当某个RegionServer挂掉,90s之后Master才能察觉到。可适当减小此值,以加快Master响应,可调整至60000毫秒。
3)手动控制Major Compaction
hbase-site.xml
属性:hbase.hregion.majorcompaction
解释:默认值:604800000秒(7天), Major Compaction的周期,若关闭自动Major Compaction,可将其设为0
4)优化HStore文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize
解释:默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
- 优化HBase客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer
解释:默认值2097152bytes(2M)用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
6)指定scan.next扫描HBase所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching
解释:用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
7)BlockCache占用RegionServer堆内存的比例
hbase-site.xml
属性:hfile.block.cache.size
解释:默认0.4,读请求比较多的情况下,可适当调大
8.MemStore占用RegionServer堆内存的比例
hbase-site.xml
属性:hbase.regionserver.global.memstore.size
解释:默认0.4,写请求较多的情况下,可适当调大