1 整合Phoenix
1.1 Phoenix简介
1.1.1 Phoenix定义
Phoenix是HBase的开源SQL皮肤。可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据。(Phoenix是HBase的JDBC类型客户端)。
可以把Phoenix理解成数据库,并且有事务,底层存储就是HBase。
Phoenix查询数据可以用sql查询的方式,Phoenix默认执行的语句到了hbase中都是大写的,除非使用双引号。
1.1.2 Phoenix特点
1)容易集成:如Spark,Hive,Pig,Flume和Map Reduce;
2)操作简单:DML命令(CRUD)以及通过DDL(建库建表)命令创建和操作表和版本化增量更改;
3)支持HBase二级索引创建。
1.1.3 Phoenix架构
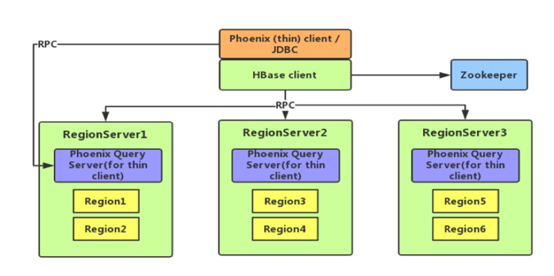
Phoenix怎么和HBase去集成呢?
(1)第一种方式:薄客户端:下图是Phoenix thin client,Phoenix thin client写Sql命令,Regionserver中的Phoenix Query server服务将其转化为Hbase语句。
(2)第二种方式:厚客户端:Phoenix thick client将Phoenix Query server服务封装到本身的Phoenix 客户端里面。Phoenix 内部直接将SQL转化为Hbase语句。
1.2 Phoenix快速入门
1.2.1 安装
1.官网地址
2.Phoenix部署
1)上传并解压tar包
[molly@hadoop102 module]$ tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module/
[molly@hadoop102 module]$ mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix2)复制Phoenix server包并拷贝到各个节点的hbase/lib:用于Phoenix 和连接hbase。分发后,重启hbase
[molly@hadoop102 module]$ cd /opt/module/phoenix/
[molly@hadoop102 phoenix]$ cp /opt/module/phoenix/phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase/lib/
[molly@hadoop102 phoenix]$ xsync /opt/module/hbase/lib/phoenix-5.0.0-HBase-2.0-server.jar4)配置环境变量
#phoenix
export PHOENIX_HOME=/opt/module/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin5)重启HBase
[molly@hadoop102 ~]$ stop-hbase.sh
[molly@hadoop102 ~]$ start-hbase.sh- 厚Phoenix连接Hbase:sqlline.py
[molly@hadoop101 phoenix]$ /opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
- 薄Phoenix连接Hbase:sqlline-thin.py
需要先启用queryserver.py,再启用sqlline-thin.py指定去找queryserver(端口8765)。
[molly@hadoop101 phoenix]$ /opt/module/phoenix/bin/queryserver.py
[molly@hadoop101 phoenix]$ /opt/module/phoenix/bin/sqlline-thin.py hadoop102:8765
1.2.2 Phoenix Shell操作
1.2.2.1 schema的操作
1)创建schema(库)
默认情况下,在phoenix中不能直接创建schema。需要将如下的参数添加到Hbase中conf目录下的hbase-site.xml 和 phoenix中bin目录下的 hbase-site.xml中
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>重新启动Hbase和连接phoenix客户端.
[molly@hadoop102 ~]$ stop-hbase.sh
[molly@hadoop102 ~]$ start-hbase.sh
[molly@hadoop102 ~]$ /opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181创建schema
create schema bigdata;
create schema if exists bigdata;注意:在phoenix中,schema名,表名,字段名等会自动转换为大写,若要小写,使用双引号,如”student”。
1.2.2.2 表的操作
1)显示所有表
!table 或 !tables2)创建表
直接指定单个列作为RowKey
CREATE TABLE IF NOT EXISTS student(
id VARCHAR primary key,
name VARCHAR,
addr VARCHAR);指定多个列的联合作为RowKey
3)插入数据
upsert into student values('1001','zhangsan','beijing');4)查询记录
select * from student;
select * from student where id='1001';5)删除记录
delete from student where id='1001';6)删除表
drop table student;7)退出命令行
!quit1.2.2.3 表的映射
1)表的关系
默认情况下,直接在HBase中创建的表,通过Phoenix是查看不到的。如果要在Phoenix中操作直接在HBase中创建的表,则需要在Phoenix中进行表的映射。映射方式有两种:视图映射和表映射。
2)命令行中创建表test
HBase 中test的表结构如下,两个列族info1、info2。
| Rowkey | info1 | info2 |
|---|---|---|
| id | name | address |
启动HBase Shell
[molly@hadoop102 ~]$ /opt/module/hbase/bin/hbase shell创建HBase表test
hbase(main):001:0> create 'test','info1','info2'3)视图映射
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作。在phoenix中创建关联test表的视图
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> create view "test"(id varchar primary key,"info1"."name" varchar, "info2"."address" varchar);删除视图
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> drop view "test";4)表映射
使用Apache Phoenix创建对HBase的表映射,有两种方法:
(1)HBase中不存在表时,可以直接使用create table指令创建需要的表,系统将会自动在Phoenix和HBase中创建person_infomation的表,并会根据指令内的参数对表结构进行初始化。
(2)当HBase中已经存在表时,可以以类似创建视图的方式创建关联表,只需要将create view改为create table即可。
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103> create table "test"(id varchar primary key,"info1"."name" varchar, "info2"."address" varchar) column_encoded_bytes=0;1.2.2.4表映射中数值类型的问题
Hbase中存储数值类型的值(如int,long等)会按照正常数字的补码进行存储. 而phoenix对数字的存储做了特殊的处理. phoenix 为了解决遇到正负数同时存在时,导致负数排到了正数的后面(负数高位为1,正数高位为0,字典序0 < 1)的问题。 phoenix在存储数字时会对高位进行转换.原来为1,转换为0, 原来为0,转换为1.
因此,如果hbase表中的数据的写是由phoenix写入的,不会出现问题,因为对数字的编解码都是phoenix来负责。如果hbase表中的数据不是由phoenix写入的,数字的编码由hbase负责. 而phoenix读数据时要对数字进行解码。 因为编解码方式不一致。导致数字出错.
1) 在hbase中创建表,并插入数值类型的数据
hbase(main):001:0> create 'person','info'
hbase(main):001:0> put 'person','1001', 'info:salary',Bytes.toBytes(123456)注意: 如果要插入数字类型,需要通过Bytes.toBytes(123456)来实现。
2)在phoenix中创建映射表并查询数据
create table "person"(id varchar primary key,"info"."salary" integer )
column_encoded_bytes=0
select * from "person"会发现数字显示有问题
3) 解决办法:
在phoenix中创建表时使用无符号的数值类型. unsigned_long
create table "person"(id varchar primary key,"info"."salary" unsigned_long )
column_encoded_bytes=0;1.2.3 Phoenix JDBC API操作
1.2.3.1 Thin Client
1)启动query server
[molly@hadoop102 ~]$ queryserver.py start2)创建项目并导入依赖
<dependencies>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-queryserver-client</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
</dependencies>3)编写代码
package com.atguigu;
import java.sql.*;
import org.apache.phoenix.queryserver.client.ThinClientUtil;
public class PhoenixTest {
public static void main(String[] args) throws SQLException {
String connectionUrl = ThinClientUtil.getConnectionUrl("hadoop102", 8765);
Connection connection = DriverManager.getConnection(connectionUrl);
PreparedStatement preparedStatement = connection.prepareStatement("select * from student");
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString(1) + "\t" + resultSet.getString(2));
}
//关闭
connection.close();
}
}1.2.3.2 Thick Client
1)在pom中加入依赖
<dependencies>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.1-b06</version>
</dependency>
</dependencies>2)编写代码
package com.atguigu.phoenix.thin;
import java.sql.*;
import java.util.Properties;
public class TestThick {
public static void main(String[] args) throws SQLException {
String url = "jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";
Properties props = new Properties();
props.put("phoenix.schema.isNamespaceMappingEnabled","true");
Connection connection = DriverManager.getConnection(url,props);
PreparedStatement ps = connection.prepareStatement("select * from \"test\"");
ResultSet rs = ps.executeQuery();
while(rs.next()){
System.out.println(rs.getString(1)+":" +rs.getString(2));
}
}
}1.3 Phoenix二级索引
1.3.1 二级索引配置文件
1.添加如下配置到HBase的HRegionserver节点的hbase-site.xml
<!-- phoenix regionserver 配置参数-->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>1.3.2 全局二级索引
Global Index是默认的索引格式,创建全局索引时,会在HBase中建立一张新表。也就是说索引数据和数据表是存放在不同的表中的,因此全局索引适用于多读少写的业务场景。
写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。
在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。
- 创建单个字段的全局索引
CREATE INDEX my_index ON my_table (my_col);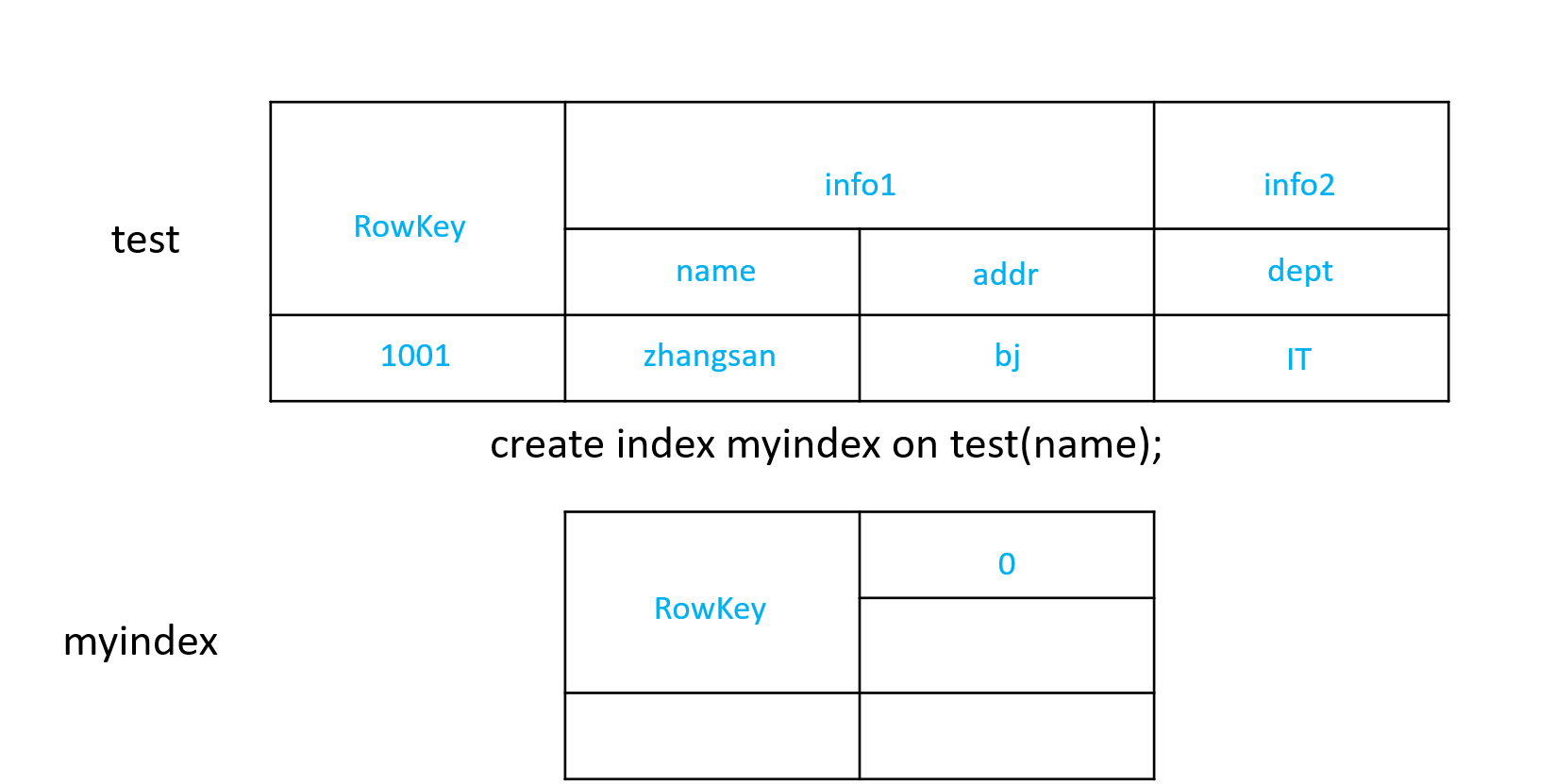
如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
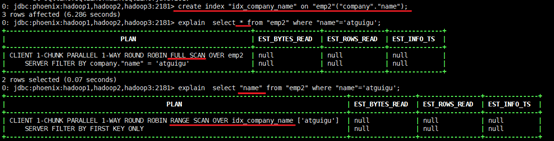
2)创建携带其他字段的全局索引
CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);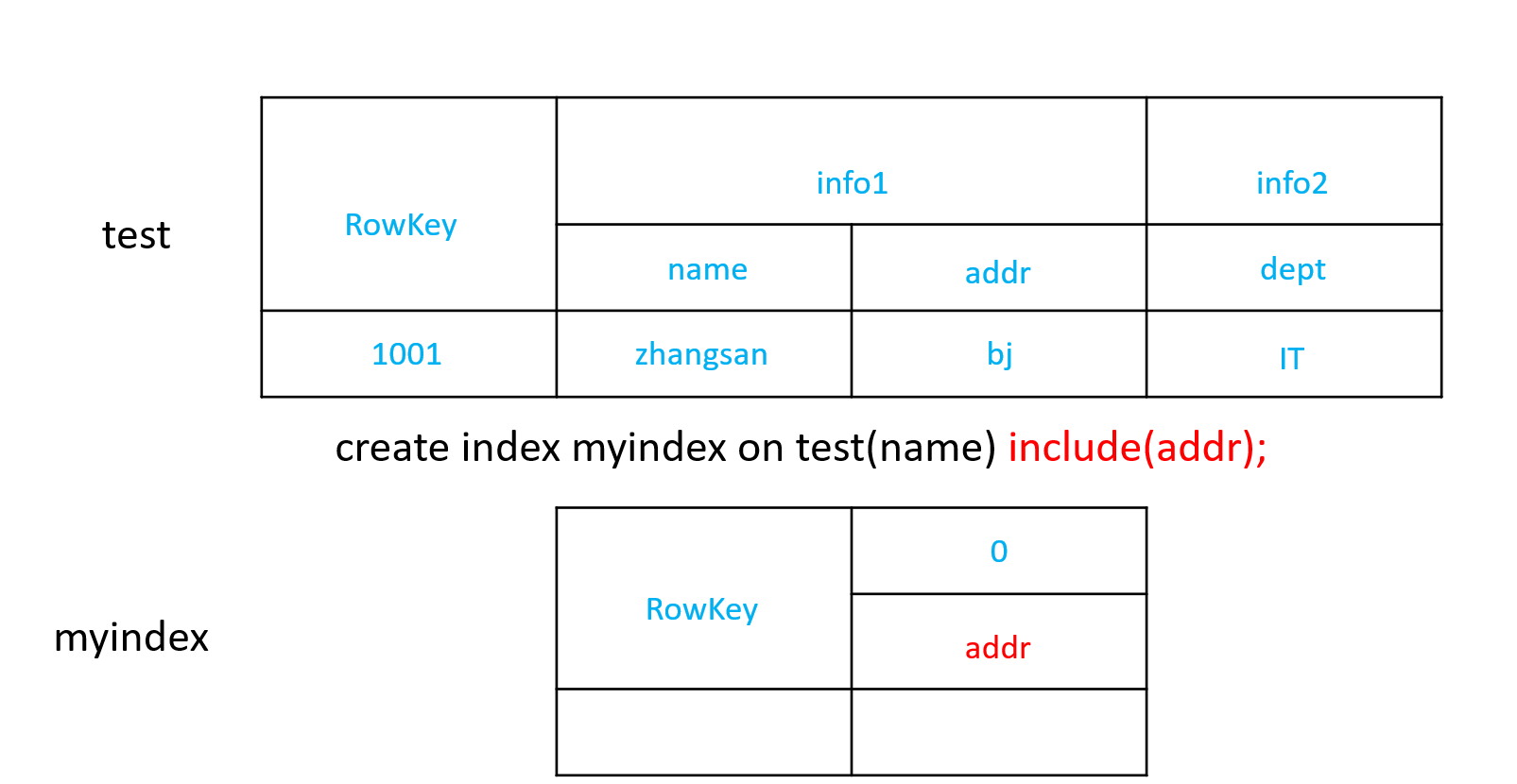
1.3.3 本地二级索引
Local Index适用于写操作频繁的场景。
索引数据和数据表的数据是存放在同一张表中(且是同一个Region),避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。
CREATE LOCAL INDEX my_index ON my_table (my_column);
2 与Hive的集成
2.1 HBase与Hive的对比
2.1.1 Hive
(1) 数据分析工具
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
(2) 用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高。
(3) 基于HDFS、MapReduce
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
2.1.2 HBase
(1) 数据库
是一种面向列族存储的非关系型数据库。
(2) 用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
(3) 基于HDFS
数据持久化存储的体现形式是HFile,存放于DataNode中,被ResionServer以region的形式进行管理。
(4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
2.2 HBase与Hive集成使用
在hive-site.xml中添加zookeeper的属性,如下:
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>案例一
目标:建立Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase表。
分步实现:
1.在Hive中创建表同时关联HBase
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");提示:完成之后,可以分别进入Hive和HBase查看,都生成了对应的表
2.在Hive中创建临时中间表,用于load文件中的数据
提示:不能将数据直接load进Hive所关联HBase的那张表中
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';3.向Hive中间表中load数据
hive> load data local inpath '/home/admin/softwares/data/emp.txt' into table emp;4.通过insert命令将中间表中的数据导入到Hive关联Hbase的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;5.查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
Hive:
hive> select * from hive_hbase_emp_table;HBase:
Hbase> scan 'hbase_emp_table'案例二
目标:在HBase中已经存储了某一张表hbase_emp_table,然后在Hive中创建一个外部表来关联HBase中的hbase_emp_table这张表,使之可以借助Hive来分析HBase这张表中的数据。
注:该案例2紧跟案例1的脚步,所以完成此案例前,请先完成案例1。
分步实现:
1.在Hive中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");2.关联后就可以使用Hive函数进行一些分析操作了
hive (default)> select * from relevance_hbase_emp;