的函数:
词频:FreqDist(words_list), 接受list类型的参数,返回词典,key是元素,value是元素出现的次数
fdist = FreqDist(dist).keys()
dist_max=set(fdist[0:50])
dist_min = set(fdist[-50:])set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
>>>x = set('runoob')
>>> y = set('google')
>>> x, y
(set(['b', 'r', 'u', 'o', 'n']), set(['e', 'o', 'g', 'l'])) # 重复的被删除1 走进KNN
1.k近邻算法的基本概念,原理以及应用
KNN(K-nearest neighbor)的基本思想非常的简单朴素,即对于一个待预测的样本x ,在训练集中找到距离其最近的k 个近邻 ,得票最高的类作为输出类别即可。当 k=1 时,则称为最近邻。
KNN常见的算法:
·Brute Force
·K-D Tree
·Ball Tree
应用:kNN 可以用来进行分类或者回归
2.k近邻算法中k的选取,距离的度量以及特征归一化的必要性
k过大时:
如果我们选取较大的k值,就相当于用较大邻域中的训练数据进行预测,这时与输入实例较远的(不相似)训练实例也会对预测起作用,使预测发生错误,k值的增大意味着整体模型变得简单。
我们想,如果k=N(N为训练样本的个数),那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型是不是非常简单,这相当于你压根就没有训练模型呀!
k过小时:
如果我们选取较小的k值,那么就会意味着我们的整体模型会变得复杂,容易发生过拟合!
k的选择:李航博士书上讲到,我们一般选取一个较小的数值,通常采取 交叉验证法来选取最优的k值。(也就是说,选取k值很重要的关键是实验调参,类似于神经网络选取多少层这种,通过调整超参数来得到一个较好的结果)
3.k近邻法的实现:kd树原理的讲解
4.kd树详细例子讲解
5.kd树的不足以及最差情况举例
6.k近邻方法的一些个人总结
2 KNN应用1
2.1 使用KNN检测异常操作
思路:
数据处理:
处理数据:
50个用户数据;每个用户15000条操作序列,每100条作为一个操作序列,所以每个用户的数据为cmd_list[150X100],其中每个用户15000条操作序列中统计FreqDist统计最频繁使用的前50个dist_max和 最不频繁使用的后50个dist_min。
KNN只能以标量作为输入。
特征:user_cmd_feature(150X3)
cmd_list中每个操作序列为cmd_block(100个命令)
f1:统计cmd_block中不重复命令的个数len(set(cmd_block))
f2: 统计(cmd_block中最频繁使用的前10个与dist_max)的交集个数(len(set()&set()))
f3:统计(cmd_block中最不频繁使用的前10个与dist_min)的交集个数(len(set()&set()))
训练:
user_cmd_feature[0:120](120X3):前120个操作序列作为训练序列,后30个操作序列作为测试序列
anaconda中创建虚拟环境
1、用conda创建Python虚拟环境(在conda prompt环境下完成)
conda create -n douge python=2.7(注:该命令只适用于Windows环境;“environment_name”是要创建的环境名;“python=X.X”是选择的Python版本)
2、激活虚拟环境(在conda prompt环境下完成)
activate dougeWindows: activate your_env_name(虚拟环境名称)
3、给虚拟环境安装外部包
conda install -n douge vulners例如: conda install -n tensorflow pandas
4、查看已有的环境(当前已激活的环境会显示一个星号)
conda info -e5、删除一个已有的虚拟环境
conda remove --name your_env_name --all6、查看pip的安装目录
pip list7、删除已经安装的模块pip uninstall **
(例如:pip uninstall numpy)
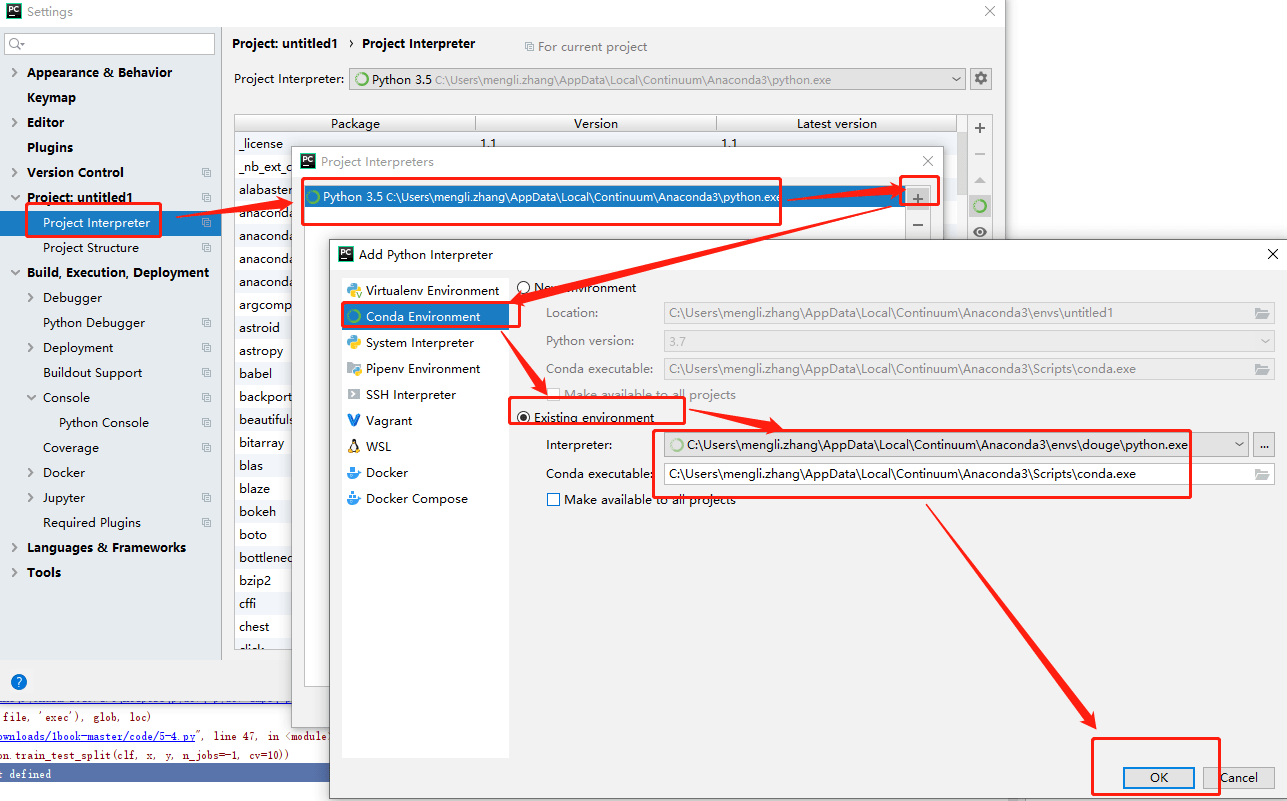
pycharm配置虚拟环境
BUG
1 cross_validation等模块弃用
新的模块sklearn.model_selection,将以前的sklearn.cross_validation, sklearn.grid_search 和 sklearn.learning_curve模块组合到一起
比如:cross_validation模块弃用,所有的包和方法都在model_selection中,包和方法名没有发生变化
将from sklearn import cross_validation
改为from sklearn import model_selection